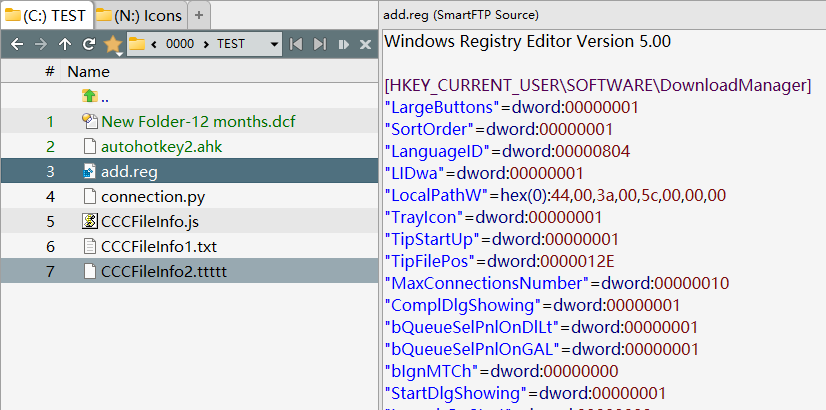
SmartFTP SourcePreviewHandler is a good AX PreviewHandler for various source codes.
It can automatically detect the encoding of a text file, and the preview is very fast.
So, I want to use it to preview .TXT file in DOpus, to avoid garbled characters in ANSI encoding (Chinese cp936,etc.)
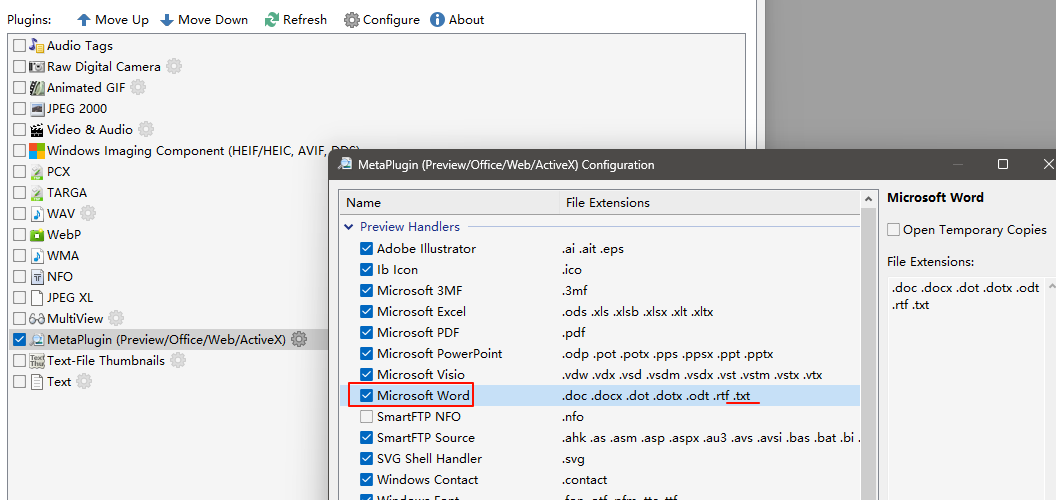
But, DOpus always can not assign .TXT to the MetaPlugin, even though I have already associated TXT with SmartFTP SourcePreviewHandler in MetaPlugin and have disabled all other plugins.
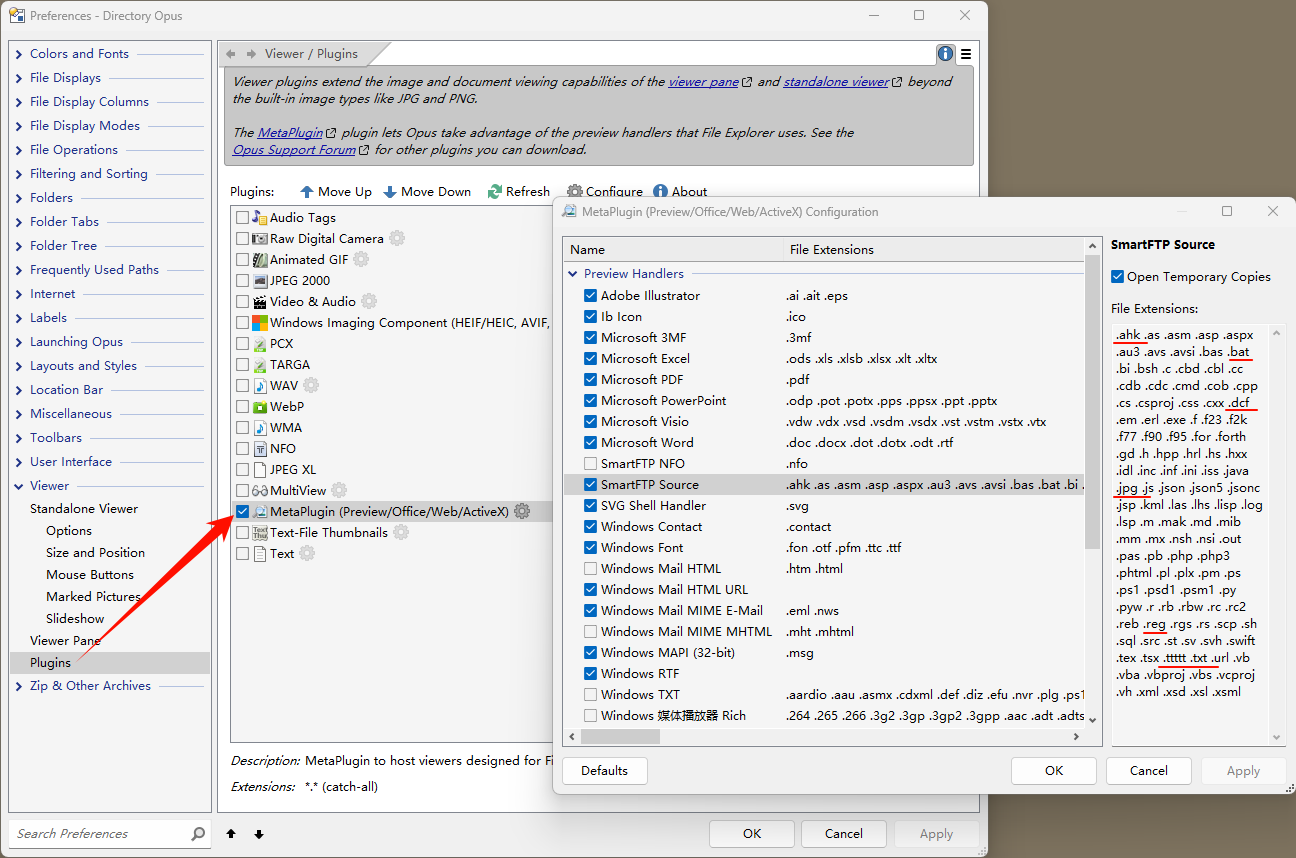
Set like this:
You can see I associate .TXT .DCF .AHK .REG .BAT ( even .TTTTT for testing ) with "SmartFTP Source".
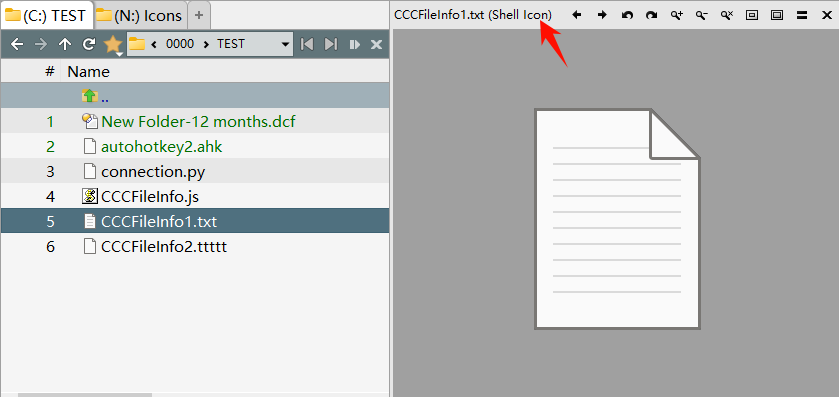
and the result is :
(TXT can not be previewed in "SmartFTP Source")
So I guess that DOpus is forcing the use of windows shell instead of MetaPlugin to preview text file when the TEXT plugin at the bottom is disabled.
Then I test associating .TXT with other Meta-plugins.
\We don't allow preview handlers to take over .txt viewing, due to the number of terrible text preview handlers out there which take over the extension as soon as they are installed and have caused lots of problems in the past. (Especially the ones that are part of PowerToys.)
I guess we could add a way to override this for people who really want to, but I question the usefulness of it for .txt files where syntax highlighting wouldn't apply.
Thanks for your answer!
Syntax highlighting is not needed for .txt file.
The reason why I use "SmartFTP Source" is that it can solve the garbled problem of UTF-8-nobom txt (such as cp936).
I think some other non English users also need it.
And, I think you can add an option to Miscellaneous/Advanced/Behavior, so that we users can enable/disable it.
Thank you very much again!
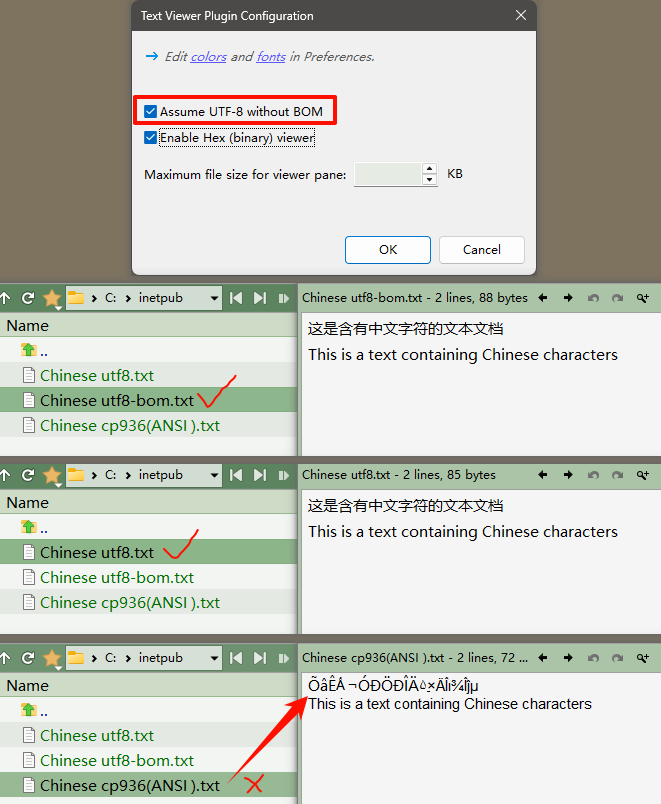
Because the default text previewer in DOpus may display garbled characters when previewing ANSI(cp936 in my language) encoding.
When [Assume UTF-8 without BOM] is enabled,
Chinese ANSI(cp936) characters will get garbled, while utf8-nobom characters are displayed normally.
When [Assume UTF-8 without BOM] is disabled,
Chinese ANSI(cp936) characters are displayed normally, while utf8-nobom characters will get garbled.
I imagine that must go wrong sometimes, since there's not really any way to know the encoding of a text file (unless it has a BOM or you have some external information specifying it).
If you can zip up some example files of both types, we might be able to make it able to guess which encoding to use to some degree, by having it assume the locale codepage if the file has invalid Unicode values in it. Not sure how well that would work without trying it.
when file does not contains bom, it is still possible to detect charset encoding based on the code point distribution statistics in file;
it is important for non-english languages such as Chinese/Japanese/Korean.
uchardet is open source project to do that: uchardet - freedesktop.org
uchardet is an encoding detector library, which takes a sequence of bytes in an unknown character encoding without any additional information, and attempts to determine the encoding of the text. Returned encoding names are iconv-compatible.
uchardet started as a C language binding of the original C++ implementation of the universal charset detection library by Mozilla. It can now detect more charsets, and more reliably than the original implementation.
History of uchardet:
History
As said in introduction, this was initially a project of Mozilla to allow better detection of page encodings, and it used to be part of Firefox. If not mistaken, this is not the case anymore (probably because nowadays most websites better announce their encoding, and also UTF-8 is much more widely spread).
It is to be noted that a lot has changed since the original code, yet the base concept is still around, basing detection not just on encoding rules, but importantly on analysis of character statistics in languages.
Original code of universalchardet by Mozilla can still be found from the Wayback machine.
Mozilla code was extracted and packaged into a standalone library under the name uchardet by BYVoid in 2011, in a personal repository. Starting 2015, I (i.e. Jehan) started contributing, "standardized" the output to be iconv-compatible, added various encoding/language support and streamlined generation of sources for new support of encoding/languages by using texts from Wikipedia as statistics source on languages through Python scripts. Then I soon became co-maintainer. In 2016, uchardet became a freedesktop project.
Thanks! For the next beta, we've added a simple test for valid UTF8 data to the text plugin, and checked it works with your scenario (i.e. those three text files, and a system set to cp936, displays all three identically).
Ironic that that page is full of character encoding errors.
Maybe in the future, but I’d rather avoid adding dependencies, and text encoding guessing is inherently imperfect and best avoided entirely by using unicode, which everyone should be using by now.