I'm hoping that Dopus is up to this rather challenging task:
I have two sets of files with video that are different in file size and resolution. However when you view the videos they are the same footage but at different resolutions.
In your example, the two filenames are identical except for the "sd" on the end. Changing the script to look for "sd" rather than " [complete]" should match them, I think.
The key problem is that I know that these are the same "series" of clips (because of the folder-names they are held in) and it's ONLY the dates in the filename that are reliable. Not even the size, creation dates or modified dates in the metadata are the same.
Do you care about the filenames staying as they are? If not, it'd be easier to rename everything so only the dates remain, at which point the duplicates will stand out.
The problem is that these files are named manually elsewhere which makes them have no predictability other than the dates. Sometimes though the extra information is useful for other unrelated reasons.
Moving the dates to the beginning can be problematic because this is a very involved workflow which involves a SQL server cataloging all of the files. I'm ok with one of the directories moving the dates (files yet to be cataloged.)
If the information in the filenames is useful, won't you lose half of it when you delete the second copy of any pair of files?
Are there any filenames where the date part will be ambiguous? e.g. Ones with other two digit numbers and dots next to the date, or multiple dates (or things which look like dates)? I think to do this will require scripting, and to write a good script will need a lot more example filenames.
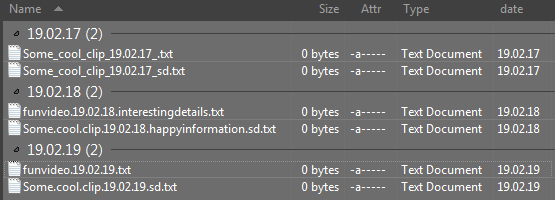
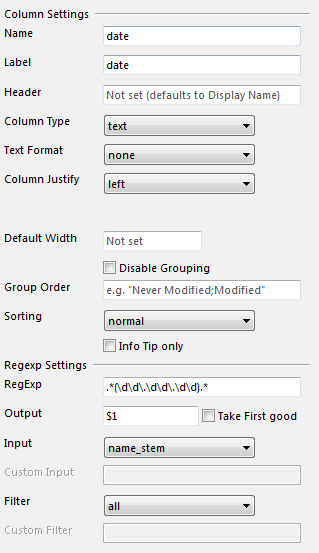
You could use the Regexp column to extract the date in to its own column. Then group by that column.
Any group with more than one item is a dupe (based on your criteria).
I don't know if you can sort by group count or hide any groups with only one item.
Would look like this
Using this config
Regexp is .*(\d\d\.\d\d\.\d\d).*
Leo yes I could lose some good (but not critical information), but if it could be left in place that would be better. For example, if one of the files has good details and one didn't, i'd likely choose the one with more details to keep.
Wowbagger, interesting idea. Those custom columns can then just be used in the duplicate files dialog?. I'm going to try this.
I tried using Wowbaggers tool and it was pretty useful if the files were in the same directory.
The problem is that they are in separate directories and it doesn't appear that I can customize the file comparison criteria to include custom columns.
So my search continues on how to solve this problem. It would be a major time saver for me if I could get this to work.
Flat view is good if they have the same parent. If the files don't have a common parent folder, you could use the search to find all files (*.*) adding the needed folders to the the search. Then add the custom column to the Find Results Lister.