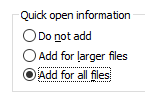
One of the best features of the RAR5 format is the ability to add quick-open information to archives. File information fields are stored in a block at the end of the archive which allows us to open and list larger archives (with hundreds or thousands of files) in a fraction of time and with minimal disk access as opposed to the traditional file seek enumeration which in turn increases search speed exponentially.
I decided to run a test by searching for a partial filename string in a folder with 660 rars (RAR5 best compression with quick open information for all files) with a total size of 55GB each containing 20~1000 files with varying level of nesting. Here are the results:
I don't know what ListFiles is but if it literally only gives a list of filenames then it's no use to us. We need the proper directory listing, including timestamps and attributes.
I was under the impression that Rar5 made listing Rar contents faster via the normal method (although I haven't tried that in depth, but it's what I read and seemed to be true from quick tests, as I recall).
That requires the archives be re-compressed into the new Rar5 format. It isn't retroactive on old archives as the problem was how the data was stored, not the code that reads the data. Older versions of the Rar format had no central directory listing, so the filenames and other basic metadata were spread throughout the archive and listing them all required lots of little reads, parses and seeks.
My understanding was that Rar5 adds a central directory listing, which would be used by newer versions of the unrar.dll when using the same old APIs as before (via the newer unrar.dll which makes those APIs do different things under the hood). That seemed to be true last time I tried it, but it has been a while and I may be misremembering.
Ineed it only helps files compressed with that specific option and is not retroactive. Could it be that the bundled unrar.dll hasnt been updated for a while? I'll replace it with the version I made tests with to see if performance is increased.
Also ListFiles seems to be just a wrapper function in the C# example doing readHeader again.
Edit: replacing the dll did not help with the situation.
ALL archives I'm testing on are created by me with the options I listed above. They're archives of project files and assets and not some random RARs from the internet. The difference is quite staggering to ignore.
I also don't see how caching might affect the c# tests and not affect dopus as it's an "operating system" thing rather than a "application level" thing.
Caching will depend on what else is going on in the system and with the files, so it could have an effect.
Antivirus could cause strange differences if it decides to re-scan the file in depth.
I can't see why there would be a difference in performance listing the files that comes down to how the code is asking for the listing, if both pieces of software are ultimately just calling unrar.dll which only has one way of listing the files that I am aware of. (Give or take the Ex functions which I think just return a few more fields and only exist for compatibility reasons since old clients won't pass buffers big enough for the extra fields.)
There are other possibilities, like something causing the archive (or other data on the same disk) to be accessed in parallel in one situation, and not in the others.
It's not caching trust me. I ran these tests multiple times.
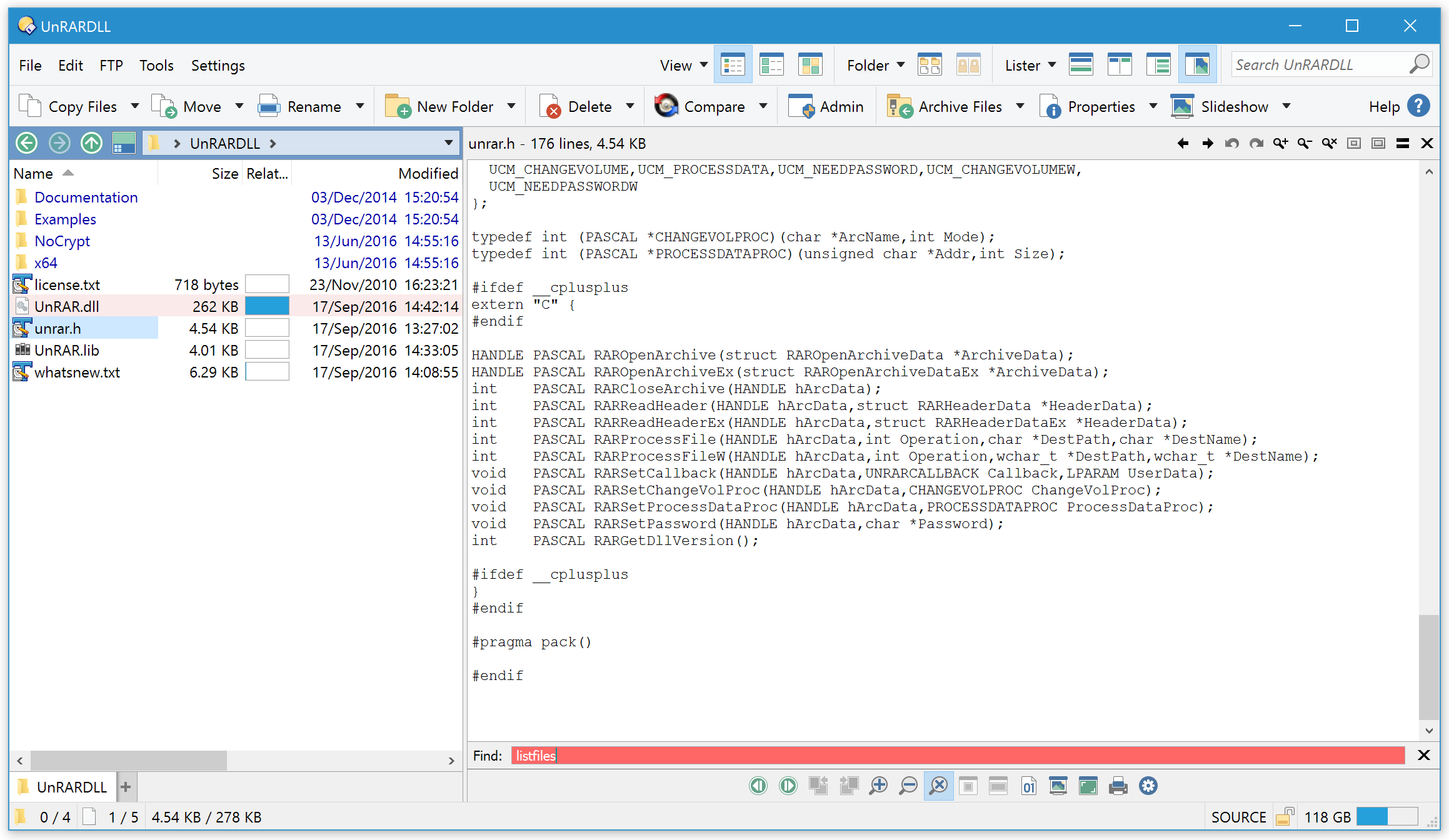
c#
using (var unrar = new Unrar(archive))
{
unrar.Open(Unrar.OpenMode.List);
while (unrar.ReadHeader())
{
if (unrar.CurrentFile.FileName.Contains(filter))
{
//do something with RARFileInfo
}
unrar.Skip();
}
}
As I did some more tests: 160 rars, 13 gb, 1600 results
test app ~ 2.7 sec
search without result window ~ 14 sec (another 90 sec of freeze time when opening the col after that)
search with result window ~ 96 sec
Testing with just Name and Location columns active (no grouping or sorting other than by filename) the search time is 6 times longer when results are being displayed while searching. Does the search only add filenames making dopus query the other information after that with another pass for each file or does dopus enjoy reading files again and again? Seems extremely inefficient.
It became apparent that the problem isn't so much related to the search method but rather with what happens when the results are being displayed. The moment the collection is displayed in the lister - all result files are being re-read from their respective archives. If I close the lister while searching, it does the reloading when the lister is displayed later. This might be instant for normal filesystem entries but takes way too long for VFS ones.
Also collections seem to be initialized with values after they are opened the first time and their xml isnt updated until that moment even though the data persists in memory.
Generating the list manually and using /col import makes it freeze for the same long time as it reads every file even though /nocheck is used - until it finally displays the results.
In my desperation I tried recreating the xml schema and generated the whole Collections\Collection.col only to find out we cannot make Dopus import a collection file (including all those fields which should not be re-read if already present).
And that's when it all became clear when hitting F5 on an already displayed collection - freeze for another minute or so.
When it rendered again - exited dopus and ran it again - navigated to the same collection - freeze again.
Even navigating away and back to the collection without restarting causes the whole re-read all over again.
In my opinion we need an optional type of no-update=true attribute for certain items in collections which should be enforced for files within archives and would instruct dopus to NEVER attempt to re-read those files' information unless explicitly forced. Instead it ought to only display the already present metadata which was imported or scanned during the initial creation of the xml. Otherwise there's no point to save all those xml attributes in the first place.
Case closed.
Also related is my shameless request to allow Collection.col (xml) loading at runtime via command as it is with text lists.