Here's a trick that might help.
Build in pieces...
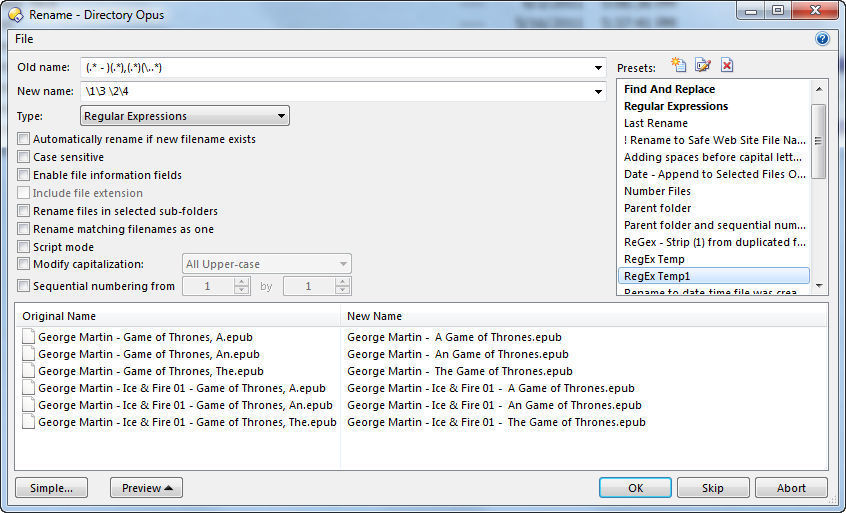
Select your files, and click the Rename button and select Type: Regular Expressions; make sure the preview window is open.
Start by entering b[/b] as the pattern (old name) and \1 as the replacement (new name). Thus, you should see that the Original Name and New Name are the same... no change.
Now, notice that you want essentially: A - B.suffix. And it is the B part you want modified - everything else remains the same. But let's start easier, instead just A - B. This is an easy enough pattern, right? It is just:
b - (.*)[/b]
Now, in the New Name, enter \1 and watch the New Name in the preview window. Now, instead, enter \2 and also watch the New Name. You should be able to see what is captured in the first set and in the second set. And \1 \2 gives you back the original, without the " - " in between.
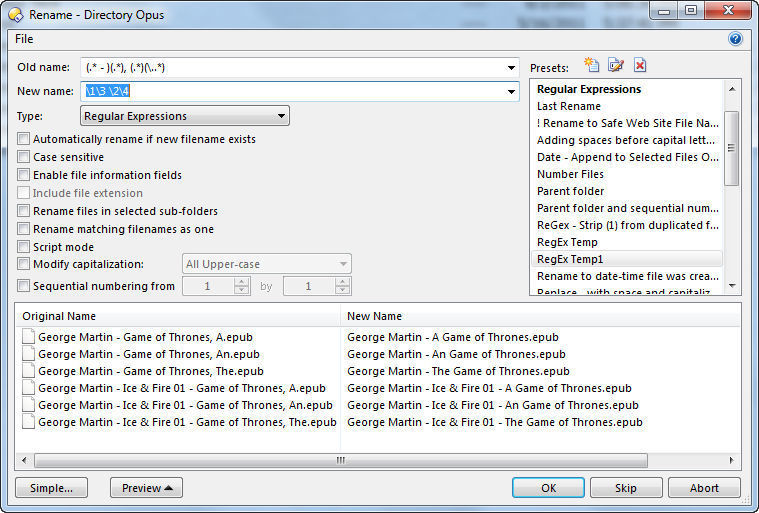
So you know you want to change the part B expression. Let's start by removing the suffix. The suffix is matched by a dot followed by anything, so that would be: .(.*) (note: we have to backslash - escape - the dot, because it would otherwise mean anything, and we only want a dot to match). So let's add the suffix part, capturing it in the capture group 3.
b - (.).(.)[/b]
Now, do the same trick. Enter \1 as the new name, see the results. Do likewise for just \2. And finally, likewise for \3.
You should see that the A part is in \1, the B part is in \2, and the suffix is in \3.
So, now, you know you need to work on only the B part, which is the second set of parens:
b - (.).(.)[/b]
Working on JUST this part, the pattern you want to match is : C, D. That's easy, right? It is just: all things not a comma, followed by a comma, space and the remainder:
([^,])(, (.))
So let's now replace our new pattern for what was part B. We need to group all this
(.) - ([^,])(, (.)).(.)
Now, do the same trick as above, cycling through, one at a time, \1, \2, \3, and then finally \4 in the New name to see what has been captured.
it should now be obvious that you can just piece them all together in any order you want using \1, etc.
One modification - take a look at the results of \3. You really don't want to capture this group. We've captured 5 things, but only want 4. So, we can place a ?: just inside the parens, which prevents capture, but still groups the items:
(.) - ([^,])(?:, (.)).(.)
Now, you have a \1, \2, \3 and \4 you can stitch back together in any order you want, but text in between as you want. Try it!