If I have been downloading various file types from the internet and have amassed a sizeable collection of stuff which I want to catalogue and keep. To this end I have been using a program called FileCategorizer to categorise them into various file types. What FileCategorizer can do at a basic level (although there are more power categorisation functions possible within the program) is to first categorise your folders by their file type extension and then create separate folders for file type extension and then finally it moves those files to the respective folders. For example, if you have a downloads directory filled at its root level with many different file types *.pdf, *.exe, *.doc, *.dwg etc etc. It will create a series of folder in sequence and then moves these files to the correct category folder. As a result, for example you may end up with a folder called Category 1 which may contain all you pdfs, Category 2 which may contain all word files etc etc.
The program will not let you use your own Category names so you have to go through each one and rename it to something which is meaningful, so for instance for Category 1, I would like the folder name to become My PDF, Category 2, My DOC etc. To do this manually takes considerable time especially if you have hundreds of Categories as a result of using this program. My immediate though was that Directory Opus's regular Expresion renaming maybe the solution but I have tried and failed. Does anybody now how to Rename a folder based on the file type extension? Better still to be able to batch process a series of selected folders in the manner described or even better not have to use the FileCategorizer program at all but have Directory Opus handle all aspects?
Looking very forward to someboby's reply, suggestion or solution.
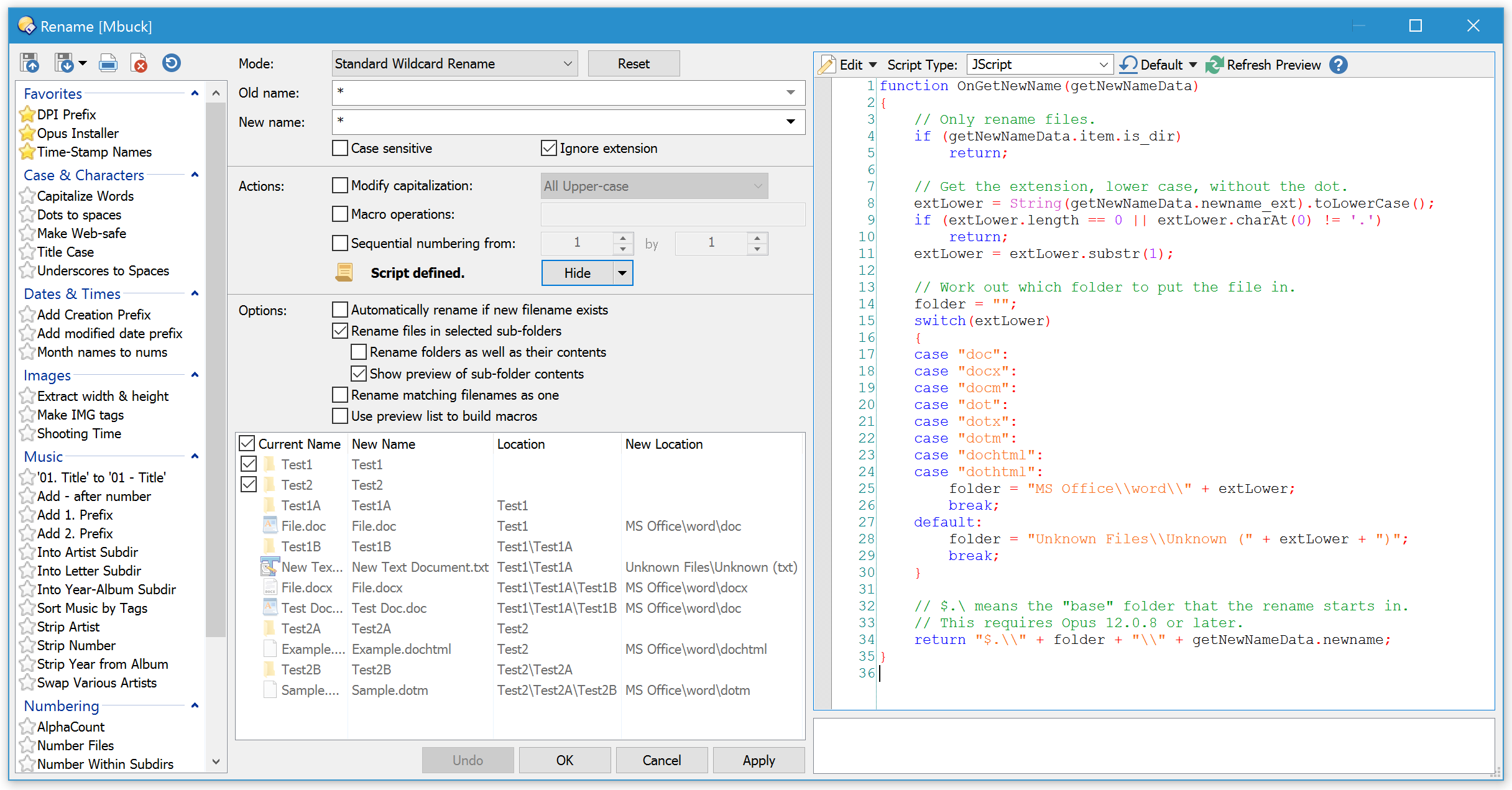
I would use the Rename feature as shown below. You can save it as a preset for convenience the next time you want to use it, and/or make it into a toolbar button.
I recently downloaded the beta version of directory opus 12 and it appears that you have considerably upgraded the naming module in the soon to be released version 12. Continuing with the discussion about auto-categorisation of files into user defined categories or based on file type extensions, do you think Version 12 would have the capability to automatically categorise / classify disparate files that one oftentimes dumps in a "To-Be-Sorted folder". Well that is what I do when I haven't got time to put the files in their correct folders. Like most busy people one never gets the time to do these boring computer housing keeping tasks. Thus, I was thinking is that somehow Directory Opus should do out of the box? How I see this working is if one could read in say a xml classification template or some other editable file format which would inform opus on how files need to be categorised into a particular hierarchical folder format. This hierarchy of folders could be predefined by Opus or User defined according to a user's preferences could be set up something like the following file format. Then Directory Opus naming function could do its thing i.e. create folders, categorise files and move them into predefined categories based on the template that defines the file categories and folder hierarchy. As I am not a programmer or directory opus power user I not sure if this can be done. Could you or someone help as I think this would be a great feature to add into Version 12 before it is released i.e. an out of the box naming method.
Easier said than done, especially when one doesn't know how to programme in Directory Opus' script language. Maybe if someone had written a good book on the subject with a title like the "The Complete Guide to Directory Opus Scripting for Dummies". Even better a streaming video course on lynda.com/. The ultimate however would be for one of the Opus Gurus to write such a script or to have it bundled as a new command in version 12 as I think this is a much-needed tool provided it can be made flexible enough so that other users can easily create their own folder hierarchy. There are some dedicated programs that one can buy that do this but usually, one would have to pay over a $100 USD to achieve what I describe, so there does appear to be a market for good folder creation and sorting and categorising utilities maybe a Directory Opus App store is a solution so as to encourage programmers to write some cool Directory Opus plugins.
I did not know that link feature existed, thank you, I have now linked my account. I hope you do get some time to do this but I think you can already see that such a feature would be a useful addition to the programme; as I am sure other users have such need also. This idea i think is a good way to enhance Directory Opus' "out of the box" tool arsenal. All these extra little features add to Directory Opus'' value and make it a more compelling purchase. For example, although I have Scooter Software's Beyond Compare I would rather use Directory Opus as its more convenient and easier to use. The same goes for duplicate file finds, although there are many products that claim to do it better than Directory Opus, again I find DO more convenient and easier to understand. So I suppose what I am saying if competitors have products that fulfil a certain need and if DO has an equivalent feature then people would be crazy to buy the dedicated programme, at least, for a general use case. Hence; DO gains further market share of the Windows Utility market. More sales would equate to more income to enhance DO features even further. I think one has to accept the fact that in the end there are those that create software and those that use software. The great thing about DO is that it enables both.
Previously you advised that a possible way to automatically categorise files and they sort them into specified folders, would be first to sort them according to the file type i.e. the files' extension. One method, explained previously would be to use the Copy MOVE CREATEFOLDER {file$|ext}. However, that may work for one file extension type but how would one process various file extension types? In other words the code would need to somehow recursively feed the Copy MOVE CREATEFOLDER command (I assume a program loop) and then move into an overall category folder. See the following schema:
Could you show me a simple code segment to achieve such a result? A concrete example is as seen below. If it is possible, then I could repurpose it i.e. copy the same example code for other extension types.
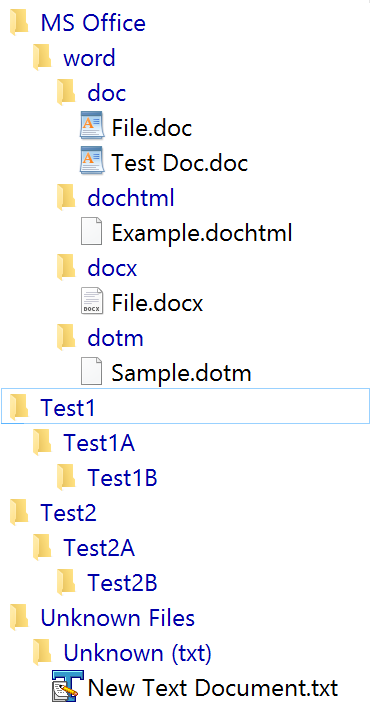
Fore example: say we start with Office Type document extensions and in particular MS Word type file extensions. Then a logical hierarchy of nested folders would be as described.
Hence such a script would first flatten the file structure, then group all the file extension types. Next, if would then find all MS Office Documents defined by the above schema. So, as a result, the script would search for MS Office documents and form a folder structure something like: Category ---> Sub-Category ---> File Extension. So for our example (which could be generalised to other extension types would look like this:)
MS Office ---> word ----> doc; MS Office ---> word ----> docx; MS Office ---> word ----> docm; etc. Obviously if the file extensions types do not exist in the flattened folder structure of files the files would remain or better still if not defined by the schema placed into the Miscellaneous category such as:
Unknown Files ---> Unkown (dwg), Unknown (pst), Unknown (mcd) etc.
So in short, if the schema is not user defined then all other extension files types are filed under the Unknown Files category.
I hope you are someone can figure this out for me.
function OnGetNewName(getNewNameData)
{
// Only rename files.
if (getNewNameData.item.is_dir)
return;
// Get the extension, lower case, without the dot.
extLower = String(getNewNameData.newname_ext).toLowerCase();
if (extLower.length == 0 || extLower.charAt(0) != '.')
return;
extLower = extLower.substr(1);
// Work out which folder to put the file in.
folder = "";
switch(extLower)
{
case "doc":
case "docx":
case "docm":
case "dot":
case "dotx":
case "dotm":
case "dochtml":
case "dothtml":
folder = "MS Office\\word\\" + extLower;
break;
default:
folder = "Unknown Files\\Unknown (" + extLower + ")";
break;
}
// $.\ means the "base" folder that the rename starts in.
// This requires Opus 12.0.8 or later.
return "$.\\" + folder + "\\" + getNewNameData.newname;
}
Sorry for not responding earlier as my laptop went on the blink and I had to replace the motherboard - fortunately, it's still under warranty. So apart from the screen its a new machine now.
So a bing thank you for doing this for me it works great.The power of opus continues to amaze me now all I have to do is learn jscript or dotnet to take advantage of its power.