The viewers can automatically decode these encodings, so I request that StringTools' decoding be enhanced. (Instead of having to study redundant JScript code.)
Test script
function OnClick(clickData) {
var tab = clickData.func.sourcetab;
var fsu = DOpus.FSUtil();
var ST = DOpus.Create.StringTools();
for (var e = new Enumerator(tab.selected_files); !e.atEnd(); e.moveNext()) {
var file = e.item();
var filePath = file.realpath;
if (fsu.Exists(filePath))
{
var fileContent = "";
var openText = fsu.OpenFile(filePath, "r");
var text = openText.Read();
openText.Close;
var textDecode = ST.Decode(text, "auto"); //var textDecode = ST.Decode(text, "utf8");
var textContent = ST.Truncate(textDecode, 2048, 0);
DOpus.Output(textContent)
}
}
}
Result:
Format Decode: utf-8 Decode: auto
UTF-8 √ × (Throwing Error, ANSI too)
UTF-8 with BOM √ √
UTF-16 BE × √
UTF-16 LE × √
Try to recognize more code pages, but the more there are, the more errors will be caused.
I deleted some code pages, in addition to the above code pages, it also supports gb2312, big5, Shift-JIS (ST.Decode cannot recognize?), but it is enough for me.
function OnClick(clickData) {
var tab = clickData.func.sourcetab;
var fsu = DOpus.FSUtil();
var ST = DOpus.Create.StringTools();
// Loop through all selected files in the source tab
for (var e = new Enumerator(tab.selected_files); !e.atEnd(); e.moveNext()) {
var file = e.item();
var filePath = file.realpath;
// Check if the file exists
if (fsu.Exists(filePath)) {
var encoding = detectFileEncoding(filePath);
var sysEnc = getSystemANSIEncoding();
DOpus.Output('File Encoding: ' + encoding + '\nIs ANSI: ' + (encoding == sysEnc ? "Yes" : "No"));
// Read the file content
var openText = fsu.OpenFile(filePath, "r");
var bytes = openText.Read();
openText.Close();
var textDecode = ST.Decode(bytes, encoding);
var textContent = ST.Truncate(textDecode, 2048, 0);
DOpus.Output('Content:\n' + textContent);
}
}
}
// Detect the file encoding based on BOM and byte patterns
function detectFileEncoding(fp) {
try {
var stream = new ActiveXObject("ADODB.Stream");
stream.Type = 1;
stream.Open();
stream.LoadFromFile(fp);
try { var bytes = new VBArray(stream.Read(4096)).toArray(); }
catch (error) { return "UTF-8" }
stream.Close();
// ================== BOM Detection ==================
if (bytes[0] === 0xEF && bytes[1] === 0xBB && bytes[2] === 0xBF) return "UTF-8";
if (bytes[0] === 0xFF && bytes[1] === 0xFE) return "UTF-16 LE";
if (bytes[0] === 0xFE && bytes[1] === 0xFF) return "UTF-16 BE";
// ================== Encoding Feature Detection ==================
var scores = { utf8: 0, gbk: 0, big5: 0, euckr: 0, sjis: 0 };
var sysEnc = getSystemANSIEncoding();
for (var i = 0; i < bytes.length; i++) {
var b1 = bytes[i];
// ------------------ UTF-8 Strict Validation ------------------
if (b1 < 0x80) {
scores.utf8 += 0.1; // Lower ASCII weight
} else if ((b1 & 0xE0) === 0xC0) { // 2-byte sequence
if (i + 1 >= bytes.length) break;
var b2 = bytes[++i];
if ((b2 & 0xC0) === 0x80) {
if (b1 >= 0xC2 && b1 <= 0xF4) scores.utf8 += 1;
}
} else if ((b1 & 0xF0) === 0xE0) { // 3-byte sequence
if (i + 2 >= bytes.length) break;
var b2 = bytes[++i], b3 = bytes[++i];
if ((b2 & 0xC0) === 0x80 && (b3 & 0xC0) === 0x80) {
if (!(b1 === 0xED && b2 >= 0xA0)) scores.utf8 += 2;
}
}
// ------------------ Double-byte Encoding Detection ------------------
if (++i >= bytes.length) break;
var b2 = bytes[i];
// GBK precise detection (only GB2312 core area)
if (
(b1 >= 0xB0 && b1 <= 0xF7 && b2 >= 0xA1 && b2 <= 0xFE) ||
(b1 >= 0xA1 && b1 <= 0xA9 && b2 >= 0xA1 && b2 <= 0xA3)
) {
scores.gbk += 2;
}
// Big5 precise detection (high-frequency character area)
else if (
(b1 >= 0xA4 && b1 <= 0xC6 && b2 >= 0x40 && b2 <= 0x7E) ||
(b1 >= 0xC9 && b1 <= 0xF9 && b2 >= 0x40 && b2 <= 0x6B)
) {
scores.big5 += 2;
}
// Shift-JIS precise detection (including common Japanese characters)
else if (
(b1 >= 0x81 && b1 <= 0x9F && b2 >= 0x40 && b2 <= 0x7E) || // Japanese characters
(b1 >= 0xE0 && b1 <= 0xFC && b2 >= 0x40 && b2 <= 0x7E)
) {
scores.sjis += 3; // Shift-JIS weight
}
}
// ================== Dynamic Judgment Logic ==================
var maxScore = Math.max(scores.utf8, scores.gbk, scores.big5, scores.euckr, scores.sjis);
// Judgment rules (priority: system encoding > Shift-JIS > Big5 > UTF-8 > GBK)
if (maxScore < 2) return sysEnc; // No significant features
if (scores.sjis >= 3 && scores.sjis >= maxScore * 0.8) return "Shift-JIS";
if (scores.big5 >= 3 && scores.big5 >= maxScore * 0.8) return "big5";
if (scores.utf8 >= 3 && scores.utf8 >= maxScore * 0.9) return "UTF-8";
if (scores.gbk >= 2 && sysEnc === "gb2312") return "gb2312";
return sysEnc; // Default fallback
} catch (e) {
return "UTF-8";
}
}
// Get the system ANSI encoding (enhanced version)
function getSystemANSIEncoding() {
try {
var acp = new ActiveXObject("WScript.Shell")
.RegRead("HKLM\\SYSTEM\\CurrentControlSet\\Control\\Nls\\CodePage\\ACP");
// Extended encoding mapping
var encMap = {
"936": "gb2312", // Simplified Chinese
"950": "big5", // Traditional Chinese
"932": "Shift_JIS" // Japanese
};
return encMap[acp] || "UTF-8";
} catch(e) {
return "UTF-8";
}
}
@WKen Is your autodecode function still the same or did you improve it in the meantime - or perhaps replace it with something else? I couldn’t find other approaches on the forum, at least not with a quick search.
In its current form it certainly does not work in all cases, but it did work in others so I found it useful. I was surprised to learn how tricky recognition can be, given that tools like Notepad++, or the good old UltraEdit, seem to recognize formats flawlessly.
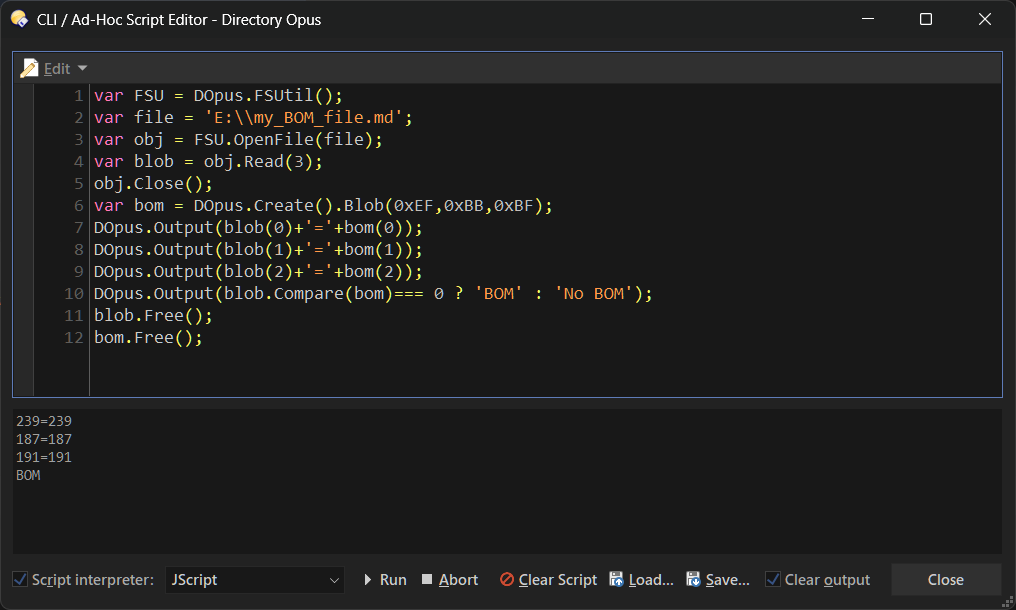
But… if you already opened the file and read the blob with File.Read(), why are you opening and reading it again using ActiveX?
And wouldn't it be enough for anyone who needs to detect encodings to just use something like uchardet (which I think is what Notepad++ uses) and move on?
I'm not sure if I'm following you or if its the other way around.
I was talking about that you don't need to open and read the file twice. You don't need the ADODB thing either.