I'm not sure if you're aware of it but there is a new but old kid on the hashing scene: Blake3 (https://github.com/BLAKE3-team/BLAKE3). Blake 1&2 were already impressive and adopted by many projects & apps but the Blake team has outdone itself this time. Blake3 has built-in multi-threading and is extremely fast. Multi-threading is a feature which except Blake2 only few and obscure algorithms have.
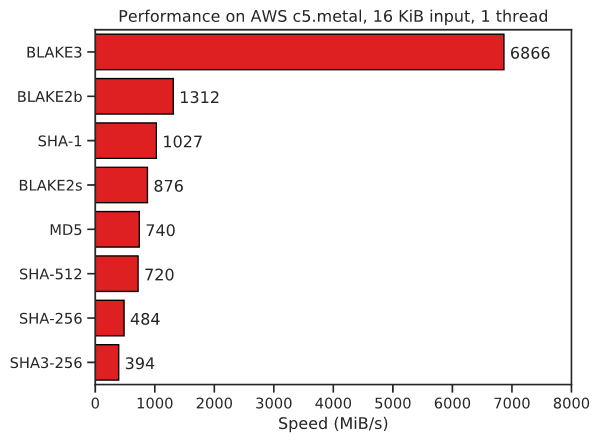
I can testify to their self-published benchmarks, based on my ongoing multi-threaded hashing development. In single-threading Blake3 beats the currently fastest DOpus internal algorithm SHA1 by leaps and bounds (300-310 MB/s vs 2.8 GB/s!), it's not even funny. And if I parallelize SHA1 with DOpus, cheat and perfectly optimize everything to SHA1's favor, only then SHA1 beats BLAKE3 but by a much smaller margin (4.8 GB/s max vs 2.8 GB/s) than vice versa. SHA1 wins only because I cheat in its favor and in an extremely unlikely situation; I reach with SHA1 typically at best 1.5-1.6 GB/s in multi-threading. And of course SHA1 is built-in to DOpus, as opposed to my script spawning CMD.exe processes for BLAKE3.
Leo said in this thread that there's a bug with files > 512 MB in SHA256 implementation. I wonder if you would consider including Blake3 when you revisit that part of your codebase or in a future DO release. Their binary release is apparently compiled from Rust but the Github page has all the C source code and docs.
The C implementation, which like the Rust implementation includes SIMD code and runtime CPU feature detection on x86. Unlike the Rust implementation, it's not currently multithreaded.
Don't let it bother you.
The C-implementation is not multi-threaded as Rust is, but because of the SIMD instructions and the algorithm (something with Merkel-trees) the hashing is CPU-internally parallelized. Note the speed benchmark is single-threaded and on my machine I see very little difference in speed even if I disable multi-threading with "--no-mmap".
As the Blake3's team results show in the image in OP, in single-threading Blake3 is far faster than SHA1, and only marginally slower than multi-threaded Blake3. My script can beat it only if I cheat and use 1 identical file per CPU thread so that no single thread takes much longer than the rest.
I'd also like to see BLAKE3 implemented as a modern choice for a cryptographic hashing algorithm. Additionally, xxHash's XXH3 and XXH128 would be useful as non-cryptographic ones.
I don't know if Directory Opus can do so already, but being able to read and verify, say, a .blake3 file would be great.
There are a few available tools out there, such as HashCheck and OpenHashTab, but in my experience, both leave something to be desired. The former is a pleasure to use but it lacks both the aforementioned algorithms (there is however a fork which contains BLAKE3 support, but both aren't maintained). The latter's high number of supported algorithms is great but overall UX of using the program I find awkward.
If Directory Opus supported a few common, modern hashing algorithms and a basic way to create and read checksum files, it'd remove the need for any additional tool.
What's the big advantage of these that would justify the time to implement them? I've yet to see them used on the web for verifying downloads, for example.
The main advantage is not to do with verifying downloads but the hashing speed at which you can create a checksum for your own files, in particular large or numerous files.
xxHash algorithms are suitable for trusted data, and for untrusted data BLAKE3. Therefore BLAKE3 may make less sense to implement, however previously in my naive comparisons, it wasn't much slower than XXH128 on multi-gigabyte files, and with the benefits of also being a cryptographic algorithm, hence I've been using it by default (even though XXH3/128 would be sufficient for nearly all data I deal with). I will probably switch to using an xxHash algorithm since the seconds in time savings will add up.
Both are much faster than the more common hashing algorithms. It probably doesn't count as a big advantage, but if you're often creating checksum files for trusted data, saving time over the currently implemented Directory Opus hashing algorithms adds up. There are however other hashing tools already in existence which I bounce between since they each seem to lack something that the other has. Directory Opus could provide a unified experience in this use case, which is admittedly likely uncommon.
Changes since 1.6.1:
The C implementation has gained multithreading support, based on
Intel's oneTBB library. This works similarly to the Rayon-based
multithreading used in the Rust implementation. See c/README.md for
details. Contributed by @silvanshade (#445).
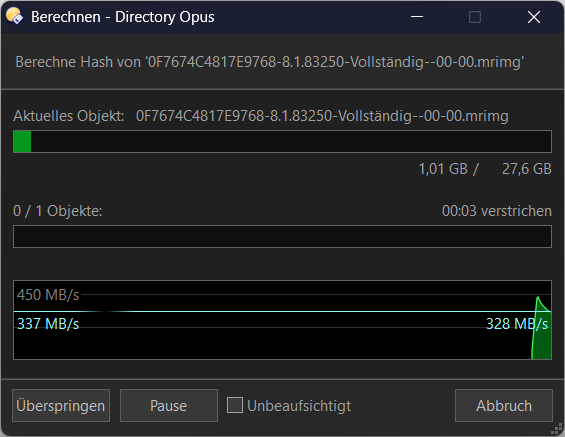
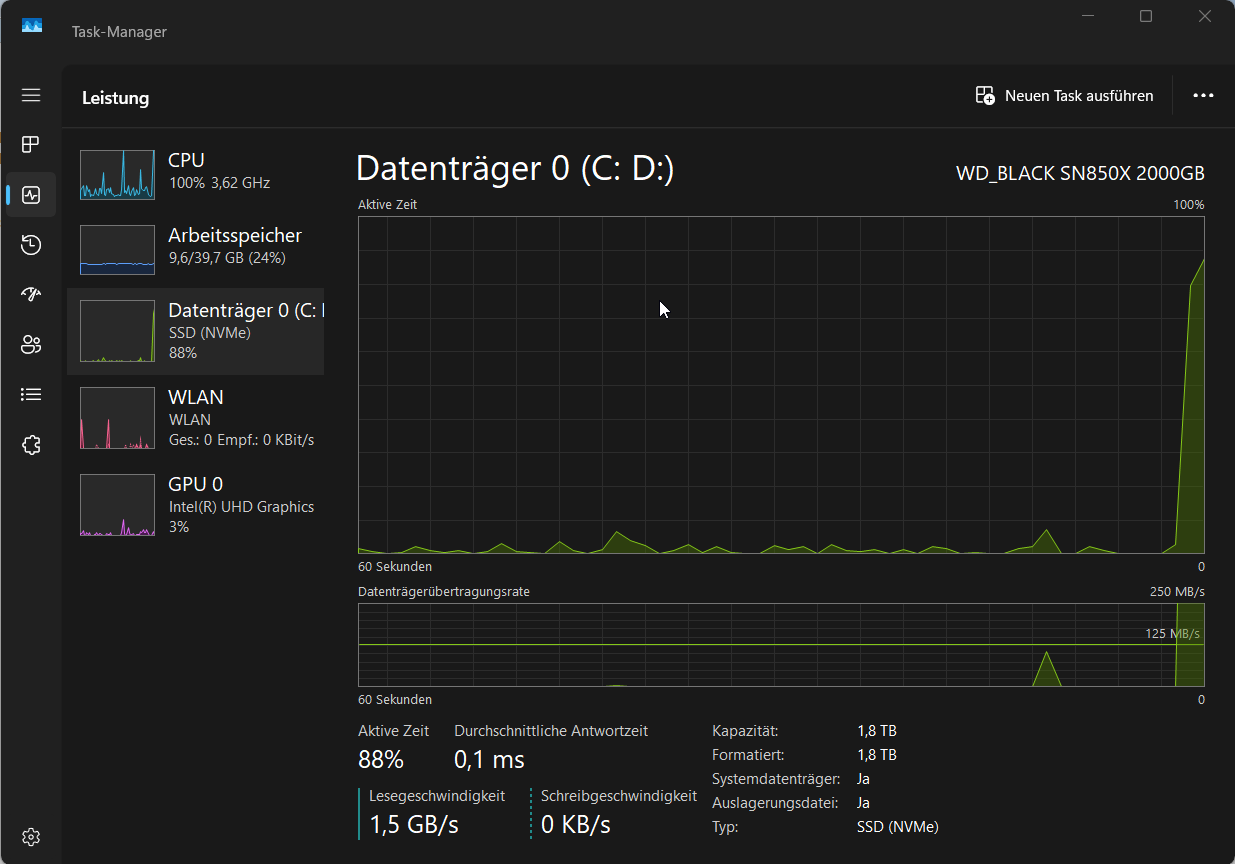
Dopus 13.15.1, 328MB/sec vs Total Commander 11.55 Release-Candidat 2, 1,5GB/sec