I perform a lot of duplicate searches these days. I sort the duplicates according to different criteria so that I decide manually which files I would keep. The problem is that the criteria are respected only inside the duplicate groups, but not between different duplicate groups. Duplicate groups are not sorted, they just stay there in a random order which may change a bit if you sort them differently, but it’s still random.
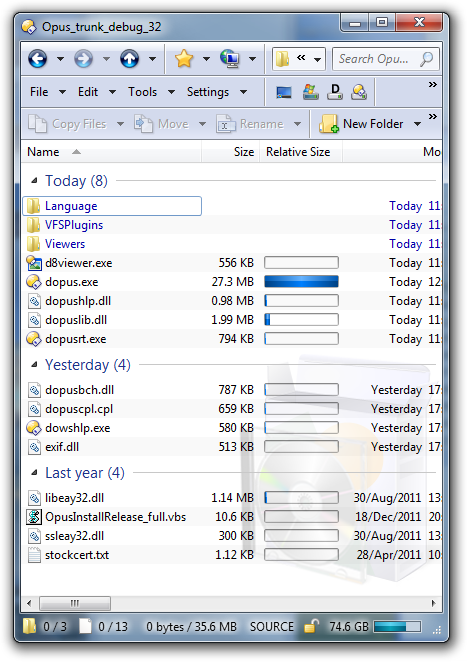
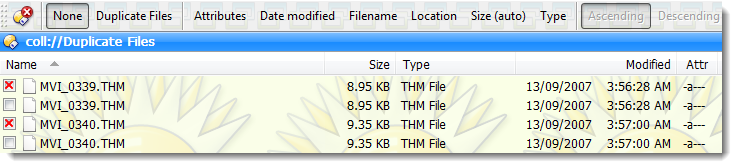
Real examples: Duplicate collection sorted by file name:
g.xls
p.xls
d.doc
e.doc
I would expect:
d.doc
e.doc
g.xls
p.xls
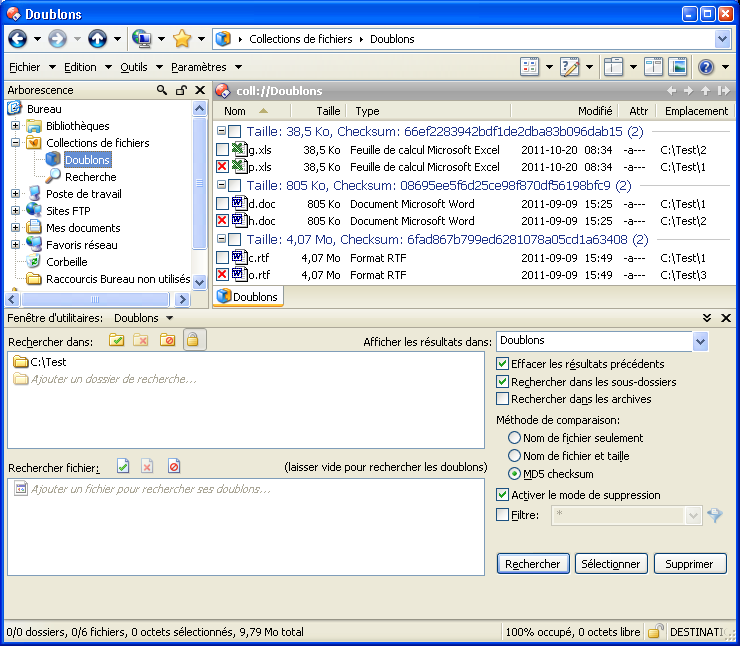
Duplicate collection sorted by location:
p.xls Folder1
g.xls Folder2
d.doc Folder1
h.doc Folder2
c.rtf Folder1
o.rtf Folder3
I would expect:
d.doc Folder1
h.doc Folder2
p.xls Folder1
g.xls Folder2
c.rtf Folder1
o.rtf Folder3
The same principle would apply if you combine sort criteria (e.g. several sort criteria at once).
Edit: No, they can't be because the names are different. So the groups are not based on the filenames, and thus the top-level sorting has nothing to do with the filenames.
The conclusion is we disagree, since I consider that duplicate groups shouldn't be put there in a random order, but they could be sorted by the same criteria as files in groups. The algorithm would be: sort files in every group by the criteria, then sort groups by the same criteria considering / starting by the first file(s) in every group, according to how they were sorted in the first step. You consider that only files inside groups should and could be sorted, thus only the first step of this algorithm could be performed.
I can't understand and don't see the logic in the placement of the groups. In the first example, why did I get files in this order instead of the one I was expecting:
g.xls
p.xls
d.doc
e.doc
I was expecting this:
d.doc
e.doc
g.xls
p.xls
Remember, the file name is the only sort criterion in this example.
In the screenshot above, what you are asking for would mean that the "Yesterday" group would come before the "Today" group, because the first thing in the Yesterday group starts with a 'd' while the first thing in the Today group starts with an 'L'.
The filenames in the groups are irrelevant to how the groups are sorted, because the groups are not based on the filenames in the first place.
In my screenshot, the groups are based on the file dates, so that is how the groups are sorted.
In the duplicate finder, the groups are based on whatever your duplicate criteria are, and that is how they will be sorted.
You understood me right and now I understand what you are saying and it makes sense for groups inside normal folders, but I don't agree with this explanation in duplicates. The examples I gave you before are in these 2 screenshots (sort order by name and by location).
It appears to me now the duplicate groups are sorted relatively by size, which I didn't ask for, because the search was performed by the MD5 checksum. But sorting groups by MD5 would be irrelevant for a human being (this is a technical information for the computer), so they should be sorted by the file name, which is the only criterion visible here.
When grouping, the top-level sorting is defined by the groups, as I said. They aren't grouped by name so they aren't sorted by name. (They can't be grouped by name for obvious reasons: the duplicates don't all have the same names in this case.)
I guess it would be possible to have some special code which changed the way groups are named or sorted for this one case, but that code doesn't exist right now, and I am not personally convinced it is needed.
Whichever way the duplicate groups are sorted, will end up be somewhat arbitrary. If we're talking about sorting duplicate groups by filenames/paths then, at best, it would use the first file's name/path. (But the group might contain a.xls and z.xls; does it make that much sense to sort that above another group containing d.xls and f.xls? To me it doesn't seem to matter.)
What's the real problem that the current sorting causes, anyway? What process are you performing where it matters in which order you inspect the duplicate groups to confirm which file(s) within each group you wish to delete?
Well, to explain you how I find this group sorting important, in my case I am sorting things on my HDD and getting hundreds of duplicates in tens of folders. But I can't just rely on DOpus's duplicate auto-select and delete, because there are dependencies between these duplicates and other files. I have to manually go through the duplicate list and manually check small groups of files. Sometimes I decide I will delete some files from the folder "PQR", which may be the duplicates of some files from the folder "JKL" and maybe "MNO" (although the rest of the files in these folders are different), but they are in a big duplicate list and even if I sort files by location, I am not always able to select all the files from PQR, because they are in a random order. So, it takes me a longer time to manually go through all the duplicate list and find files from PQR than if I had a way to automatically select them or at least have all of them grouped by some sort criteria; then I continue my work and I go to their folder and check all the dependencies and prepare the 7z archives and so on. Then I go back to the duplicate list and start working on something else; however, sometimes I may notice that I missed some duplicates in the PQR folder, so I have to start again. It gets frustrating.
Let me add that, in the case I mention, I can't narrow the duplicate search.
Well, I try to use different intelligent criteria to sort my files. In many cases they are the file location, but not always. Or I would need the first criterion as location and the second one as the file name. I have never needed the file size as a sort criterion. I hope my example was clear enough that an arbitrary order is not the best one.
Besides my specific need, I think it would be a good idea to be able to sort groups inside the duplicate list by specific criteria.
I just started using v10 of Opus and I'm just starting to complain. So much has changed that seemingly cannot be changed back to the previous behaviour.
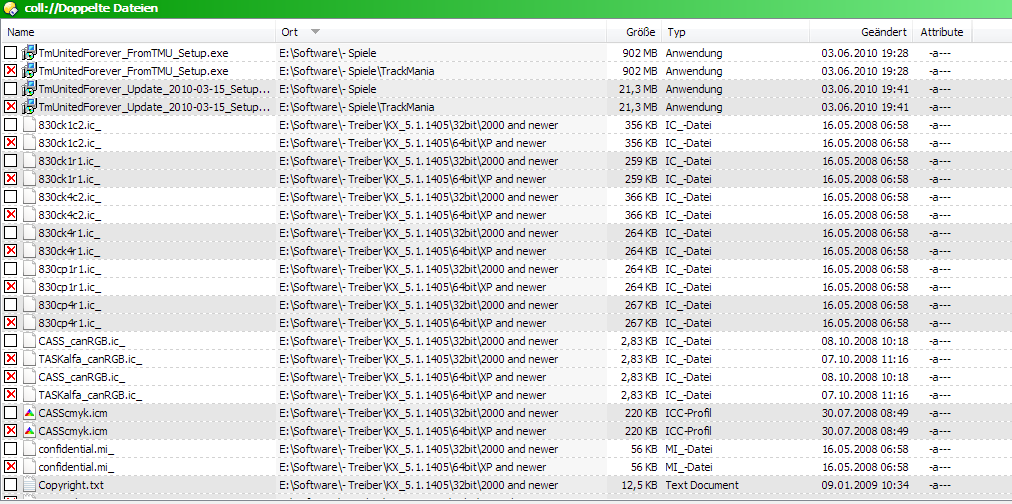
I came here via research because I was equally confused by the sorting/grouping when looking for duplicate files. When doing a search for duplicates by MD5 hash, then both Opus9 and Opus10 will group the result by tuples of files with the same hash. Opus10 adds the grouping line with size and checksum information and a count of the files in the group. First complaint: When searching duplicates for cleanup, this line is meaningless, it distracts from looking throuch the files and it makes it more complicated to manually select files for deletion (the automatic delete option almost never selects the files from the correct place).
The bigger problem: Changing the sort will just sort the files inside the groups, but it will not sort the groups themselves, just what the topic starter complained about. This is because those group headlines are now treated independently from the files. This makes sense when grouping by date, but it makes absolutely no sense when searching for duplicates. Here the grouping lines are hardcoded to begin with file sizes, so groups are always sorted by ascending or descending file size and nothing can change that. This is a regression! In Opus9 simply changing the sort order would resort the duplicate tuples by place or date, just as intended.
From my point of view, it should be possible ("use simple grouping" checkbox or something like that) to completely disable the whole new grouping code of Opus10 when searching for duplicates. The implementation in Opus9 had a much better productivity in this specific situation.
I already see me installing Opus9 in a virtual machine just for its much better find duplicates feature. D-Oh! New features are fine, but then please always provide a path back to the old behaviour.
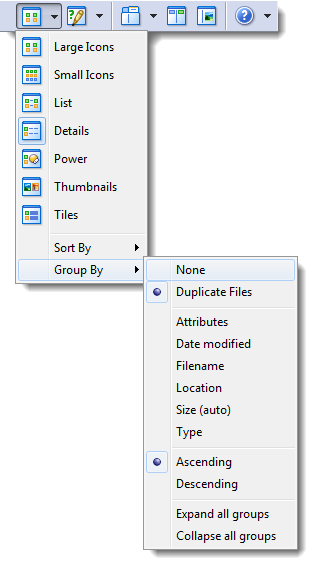
Thanks for the reply, but this is not a solution for the problem. Completely turning off the grouping will... turn off the grouping (g). This means that duplicate files do not stick together anymore and changing the sort order will sort all the files in the collection independently. In Opus9 the grouping always kept the duplicates together but it also allowed to sort the list of duplicates. Opus10 does not allow that anymore because changig the sort order only acts inside each duplicate group but not on the groups themselves. To reproduce the problem please do a search for duplicates by MD5 on a big folder hierarchy and then try to sort the result by location. With grouping activated, only the contents of each group will be sorted, with the order of the groups staying the same. With grouping deactivated, the duplicates will not stay together when changing the sorting.
I've often had difficulty using the Duplicate find feature for this same reason... and to AllOlli's points, I think the sort of changes that would be needed would be:
allow 'sorting' of Groups against a different criteria than is used to do the actual grouping itself
allow independent sorting of both the 'Group Members' and the 'Groups' themselves
I don't know if many people would find this useful OUTSIDE of a Duplicate Files search or not though, where the kneejerk assumption would be to allow the sort of sort tweaking described here to be lumped in as part of the folder format facilities. But if not, then for dupe searching only - I'd be happy to have a drop down in the Duplicate Files search dialog (and presumably the 'Find DUPES' function) that would allow setting the 'Group Sort' criteria.
I'd likely use the 'Location' value as well for the sorting of the groups - but also as the sort 'within' the groups (sorting of the group members). But that's based on the specific scenarios in which I usually want to use Find DUPES in the first place... which is that quite often I've got "sets" of related duplicate files. Meaning - I may search for dupes across MANY folders, and in one of those folders I will likely have a "series" of related files (say 10 related files) - all or ~some of which may have duplicates in one of the other folders. While AllOlli didn't elaborate on his comment that "the automatic delete option almost never selects the files from the correct place"... what I've seen is that if the two folders that contain the dupes are folder1 and folder20 (for example), the automatic selection of dupes sometimes marks ~some of the files in "each" of the folders for deletion instead of always marking the ones in folder1 -or- folder20 for deletion. In and of itself - I think this is probably a separate "issue" from anything having to do with the sorting behavior we're really talking about... but the way in which the group sorting is handled makes the manual reviewing of the deletion selections that much more difficult; particularly if you've got multiple duplicate "sets" of files spread across many folders.
At any rate - didn't mean to sidetrack the main point of the grouping behavior. ++1 for allowing a 'Group Sort' criteria to be specified for dupe searches that is separate from how the groups are defined as well as separate from how the items within the groups (group members) are sorted within the group...