This thread makes no sense to me. Opus 9 did not allow sorting of the groups at all. And I can't understand how you would sort the duplicate groups in any meaningful way given that the groups themselves consist of files that are the same (other than the way they're already sorted, which is arbitrary but the only way I can see that makes sense).
Sorry that this answer took so long. But I hadn't much time and I knew it would take time to write it.
Well if it didn't allow sorting at all than either you are talking about the sorting that Opus10 supports (inside each group) or I have been using the completely wrong program labeled "Directory Opus" for the past years. Sorting groups did not work completely as intended but saying Opus didn't allow it at all can only mean that you are talking about the group contents and not the groups themselves.
First of all I am now writing exclusiveley about "find duplicates", not about groups in any other context. Both Opus9 and Opus10 have groups. A group contains all files that are considered as duplicates of each other. In Opus9 the grouping just resulted in a change of the background colour between grey and white. In Opus10 a group has a headline containing information about the group and its contents depends on the method used to find duplicates. Here is an example:
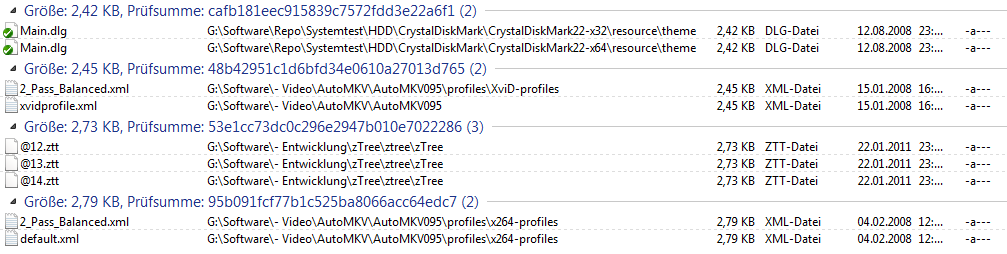
We see four groups, the biggest of them containing three files. The groups are sorted by their headline. They are always sorted by their headline because there are no options to change that besides reversing the sorting. When using MD5 then the headlines begin with the file size so the groups are sorted by file size. The contents are the groups are affected by the GUI controls for sorting so that allows to sort the contents of each group by whatever. The order of the groups is never affected by this.
Now examples for Opus9.
Groups sorted by size. This is exactly the same only sorting available for groups when finding duplicates by MD5. Since all duplicates in a group are of the same size it is easy to sort the groups:
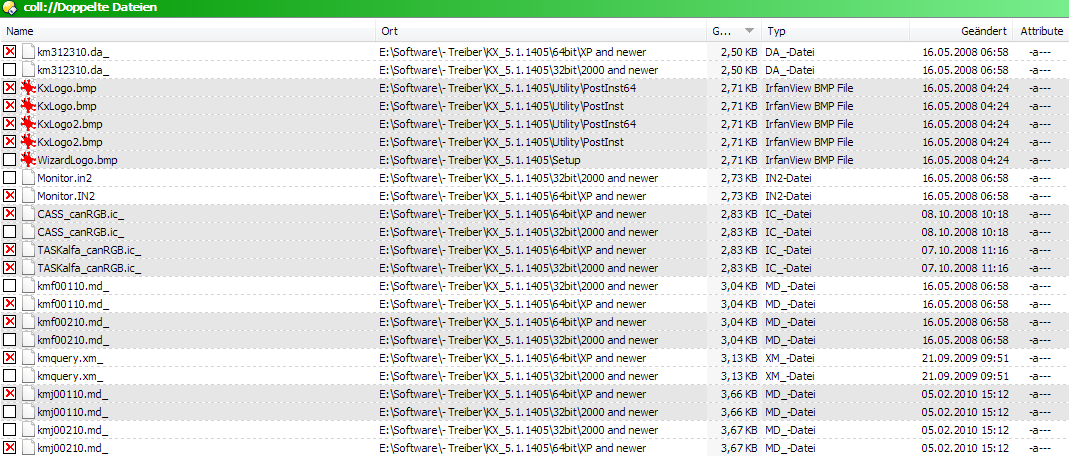
Now sorted by location. From now on all the sort orders aren't available anymore in Opus10. Here the groups are sorted by where their contents are. Because the members of a group may be at totally different locations I suppose that Opus sorts each group by the lowest sort result obtained for all of its members or the highest for reverse sort order. It may also be that it just blindly uses the first file that was put into the group for sorting the whole group but usually that works really good:
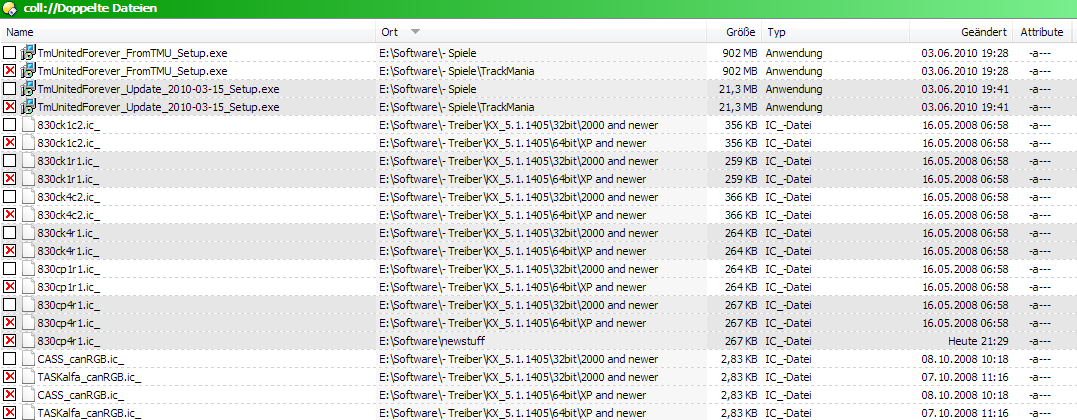
Now sorted by file name. Here we can see that the group containing the "CASS_" is put before the group "CASSc" and before "con" and so on. The sorting works completely as intended:
Now sorting by type. Not that this is very useful but it works: "Anwendu..." is put before "CH_" before "DA_":
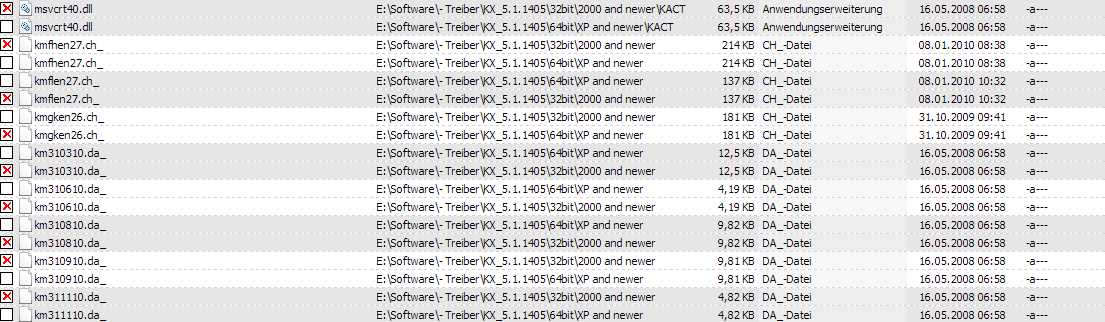
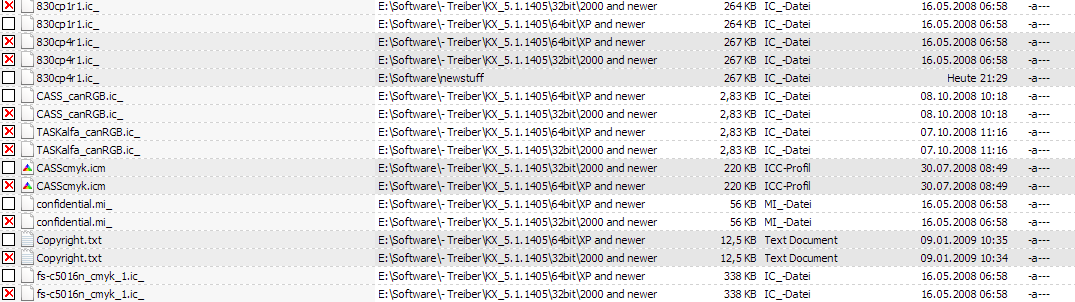
Now the one that wasn't working when I built my example pictures: sorting by date. We can see that another group containing a file from today ("Heute") is shown deep down. I would axpect containing the most recently changed files come first and those where all members weren't changed for years would come last (or the other way round depending on sort direction). This sorting would be useful for manually cleaning up duplicates in a big directory were some duplicates are meant to stay. You can copy new files deep into the tree structure and then, wehn finding duplicates, you only have to look for the duplicate groups containing the newest files:
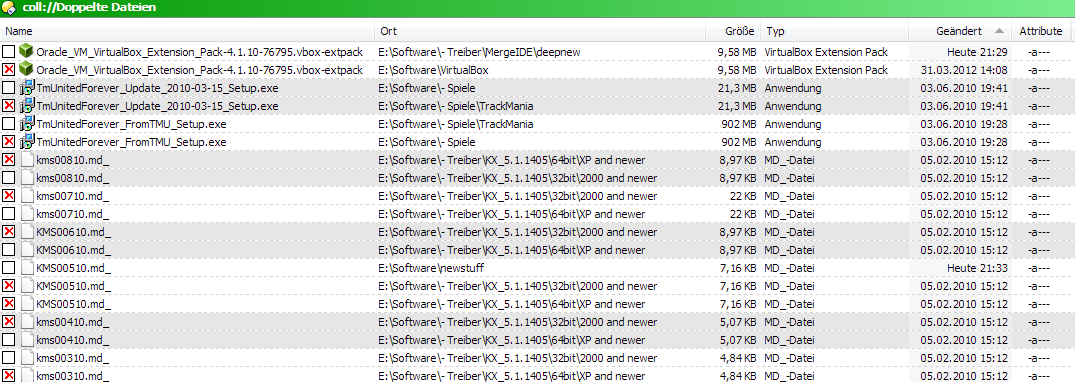
That concludes the examples for sorting groups in Opus9. It would be nice to bring that functionality back.
On top of that I have to add that, when manually cleaning up duplicates then the new headline from Opus10 is in the way because the user needs to focus on the file locations or dates when selecting duplicates to delete. Therefore there should be an option to turn off the group headlines and bring back the alternating background colours or in other words, bring back the display of Opus9. In other contexts beside finding duplicates the headlines are fine, but here they can be distracting.
I'm sorry to read that, but I have to disagree and this thread shows that it makes sense to at least some users that files (even in the duplicate collection) in an evolved file explorer should be presented in a specific order, but not in an arbitrary one, and that there are good ideas presented in this thread to do that. As stated above, the meaningful way of sorting files would take in consideration some properties of the files inside groups, taken into account one after another inside the same group.
I think we've understood things now, from the examples given. At least, I have.
It's on the list of things to look into, to see if we can do something along these lines.
Thank you, leo, and looking forward for the result.
Leo, any news about this problem?
No. (We have a huge to-do list. We'll update the thread and/or put something in the release notes when there's anything to announce.)
Just wanted to add my 2 cents. It seemed to me that in prior versions of DO when I would search for duplicates across folders by checksums that the results returned were ordered by the way the directories were included in the initial list to search across. If you listed three directories (XXX, AAA, RRR) you would get your duplicates of a single file with all dupes in XXX, then AAA then RRR regardless of the file name.
file r in XXX
file t in XXX set for delete
file t in AAA set for delete
file p in RRR set for delete
file t in RRR set for delete
All the above would be dupes of one another but it was never random as to how they displayed.
That seems to have changed!
Today when I did a dupe finder, sometimes I would get the RRR first even though there were dupes in AAA and XXX which used to be listed first or as I said by the order the directories to be searched were added. I know this use to work because I typically would compare a new directory against several older directories and as long as I setup the new directory (I can't remember anymore if it was first or last) it would always auto delete the newest files and I wouldn't have to time going through them.
Almost forgot. The whole reason I was searching on this subject was because I noticed the change in the order and came to see what exactly was being used as a tie breaker to determine the order.
[quote="cityguy"]Just wanted to add my 2 cents. It seemed to me that in prior versions of DO when I would search for duplicates across folders by checksums that the results returned were ordered by the way the directories were included in the initial list to search across. If you listed three directories (XXX, AAA, RRR) you would get your duplicates of a single file with all dupes in XXX, then AAA then RRR regardless of the file name.
file r in XXX
file t in XXX set for delete
file t in AAA set for delete
file p in RRR set for delete
file t in RRR set for delete[/quote]
This thread is about how the duplicate groups are sorted.
How the files within the groups are sorted has never changed:
[ul][li]They are sorted according to how the file display was sorted before you ran the duplicate finder.[/li]
[li]They can also be re-sorted by changing the file display's sort order and clicking the Select button near the bottom of the Duplicate Finder panel (assuming you are in Delete mode).[/li][/ul]
You may need to add the Location column and sort by it.
I know it's about how the data is sorted within the groups. That's exactly what I noticed had changed. Before it appeared ordered by the way I entered the directories and now it appears random.
I haven't changed anything in my setup. I'm not sure why the results have changed but like I said I never had to do anything special before other than make sure my directories were specified in the correct order prior to starting the process. I've never clicked on the "select" button, didn't even know what it's purpose was. I'll give it a try next time to see what it does and see if it solves my problem.
The thread is not about how the data is sorted within the groups.
It's about how the groups themselves are sorted, not how what's inside each group is sorted.
This has gotten very complicated for me but I would like to repeat a couple of points that Leo made that I stumbled upon myself and which help me with my dupe finding
[quote="leo"]
How the files within the groups are sorted has never changed:
[ul][li]They are sorted according to how the file display was sorted before you ran the duplicate finder.[/li]
[li]They can also be re-sorted by changing the file display's sort order and clicking the Select button near the bottom of the Duplicate Finder panel (assuming you are in Delete mode).[/li][/ul][/quote]
The first point is the most important. Changing the file display before finding Dupes greatly effects your results. Another trick that might come in handy, when finding Dupes below ONE folder, try using Flat View. It can help you understand the total pool of data that you are working with and which way of pre-sorting works the best.
I think Leo's second point was lost on some. Once you have your list of duplicates and you don't like the choice that DOpus has made for deleting (checkboxs), sort the dupes a different way and then click the Select button. DOpus will then re-select the checkboxes, always leaving the top-most one as the "keeper".
Well, the latest developments (10.1.0.3 and 10.2.0.1) make things more difficult:
-
10.1.0.3 reverted the order of date and size fields. I don't know whose idea this was, but it was a bad idea in general in my opinion. Usually, when I sort my files, I want to have them in chronological order or from the smallest to the biggest. But with duplicates, it's worse, because if you sort them by date, DOpus will automatically select to keep the most recent find instead of the oldest. Every time I have to click twice on the date or size fields. In the past there was an advanced option that allowed you to revert the sort order. It's a shame this option wasn't even proposed as an alternative for the 10.1.0.3 change.
-
10.2.0.1 "Added an option to the Duplicate File Finder to number the duplicate groups rather than using the search parameters to describe the groups" Maybe this is an incomplete try to allow users to sort duplicate groups as they want (This was the reason I created this thread.) But, we don't really know how the digits this option created are useful. Moreover, after I used this option once, now it's gone and it doesn't appear anymore on new duplicate searches!
You can change the default sort order from Preferences / Display / Fields.
What do you mean the option is "gone" ?
What a relief! I didn't see this information in the change log. Thank you
I turned on "Folders / Folder Display / Add 'Group' column automatically when file display is grouped" and "number duplicate groups" in the duplicate search panel, but the group column doesn't appear anymore in the duplicate tab when I perform the duplicate search.
That's because it hasn't changed ![]() You've always been able to reverse the default sort order of each field that way, all that changed was the default sort order of a few fields.
You've always been able to reverse the default sort order of each field that way, all that changed was the default sort order of a few fields.
If the Group column has been turned off somehow you can turn it back on in the same way you can turn any column on (right-click on the column headers, or use the Folder Options dialog).
The option to add the column automatically only takes effect when the display as actually set into group mode; if you have, for example, a folder format saved for a collection with grouping turned on but the Group column turned off, the option won't have any effect.
I was able to have the group column back for a while, but it looks like it doesn't stay there between duplicate searches. You have to set it manually almost every time, regardless of the "number duplicate groups" checkbox.
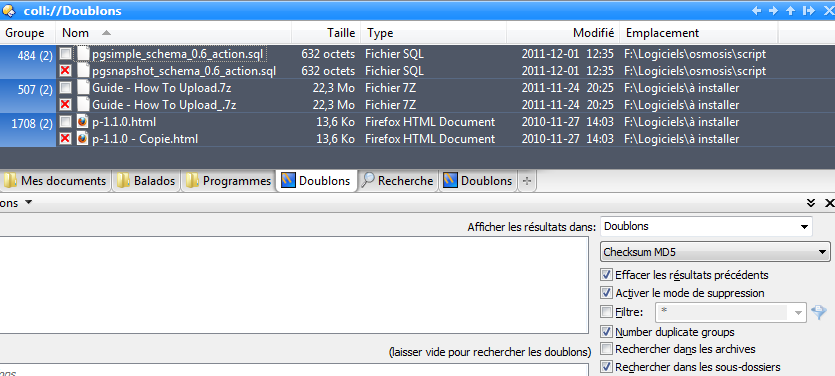
Anyway, it's still not clear to me what this group digits represent (see the screen capture). It's obviously neither the size nor the MD5.
You probably just need to save the folder format for the Duplicates file collection (see the Folder Formats FAQ for details).
Okay, I will try that.
What about to the digits appearing in the group column in the screenshot above? How are they useful?