Introduction:
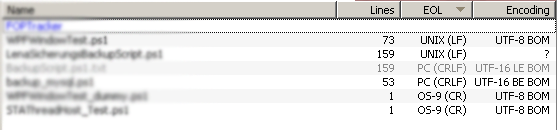
A set of columns providing information about files.
Columns:
Lines - number of lines
Rating - rating (stars) of items
EOL - line endings (UNIX, PC etc.)
Encoding - file encoding (UTF8-BOM, UTF16 etc.)
FirstLine - first line of text/ascii files
Notes:
Add your own file extensions in case they are not pre-configured yet in the script config section.
Original idea by Kundal (and a button version as well): Text file line count
This version adds script config, some extensions, supports 0byte -> 0lines, is case-insensitive and 33% faster (noticeable for bigger files).
Encoding detection is stolen and reshaped from user Qiuqiu (Column text file encoding).
Installation:
To install the column, download the *.js.txt file below and drag it to Preferences / Toolbars / Scripts.
After that, right click any listers column header and add the columns from the "Scripts -> FileInfo" submenu.
Download:
Latest:
v1.3.3 / 2017.11.20 - new column Rating, fix for uppercase file extensions being ignored Column.File_FileInfo.js.txt (21.4 KB)
Man, you and others keep coming up with great script ideas.
I haven't kept up with all the new creations since writing the pages about scripts and the file naming convention thingy on dearOpus. Need to look at all the new goodies and update, will try to do that soon.
Thanks for all the great scripts. I use ListerDoubleClick constantly.
Thanks! o) That's currently by design, since proper detection of UTF-8 NoBOM always involves analysis of file content and a good portion of guessing and assuming the right thing. The Encoding column currently does not use very sophisticated methods to detect the encoding, it just checks for existing BOMs. But: If you look at the source, you'll find a "todo" entry to eventually add the "magic" which Editpad Pro and others use to also detect UTF-8 for NoBOM files "correctly". Cannot say when this will happen though, support for analysing any kind of file data by DO is given, so.. o)
Now that you ask, I probably should edit some more text in the initial posting. It's an attempt to show exactly what the regular Rating column shows, just with plain text/numbers (5 stars = "5"). I'm not sure yet this works 100%, as my impression is, that there is no way to get the very same rating via scripting? The column also is not restricted to text files, misleading description, will fix! o)
Yes, I think that's what's used right now. But a past investigation showed, that rating can be in meta.doc as well for the same type of files, while meta.other being null/undefined. So the question is, what "chain" does DO run through to determine the rating for the rating column. Is it meta.other first, then meta.doc or the other way round? What about ratings in meta.audio etc.. You know what I mean? I probably can check them all, but I think the determined rating can still be different to what DO shows in the native Rating column - maybe I'm wrong here. I remember it being difficult to yield the same rating values. It's some months since then.. don't mind me talking bs. o)
Not sure, but if it is doing that then the main Metadata object's string value will tell you which sub-type to go for, which is probably the best bet to pick up the rating from.
Allow me revive this old thread.
Have searched and search on Internet to find a tool that lists the text encoding. In vain.
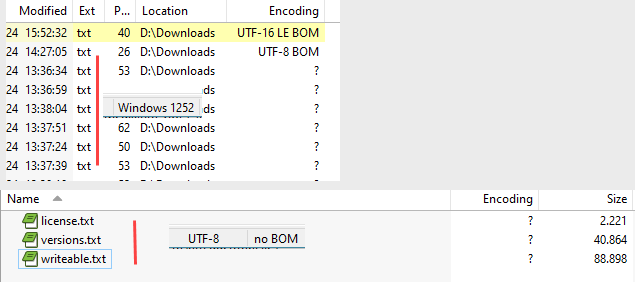
I stumbled over this script. Looks wonderful! Really. However, in many cases the column remains empty (extension .srt) or a question mark (.txt). When I open the files, they appear to be Western 1252 or UTF-8 no BOM
Right now I need to open each and every file to see the encoding.
Not sure if it is possible to extend the script so it handles .srt files (or any txt file like, such as .ini) to include 'no BOM' and Western 1252 ?
The built-in Description column will report text types when there is a BOM.
When there isn't a BOM, there isn't any reliable way to know a text file's encoding. You can guess, and test if something uses characters that seem outside what would normally be used in a given encoding (which can only tell you it probably isn't that encoding, not what encoding it actually is), but it's guesswork and goes wrong all the time, unless you know something about the text files to weight the probabilities (like "they all came from Windows and only people who wrote in Greek").
Coincidentally, I just now stumbled over a tool that is named "EncodingChecker v2.0" (on Github).
The interface looks nice, but regretfully I can't find a downloadable file and site being for developers, am afraid I can't make heads or tails of it.
Anyway, thanks again.
I have created a plugin that shows the file encodings: File MIME type column
It should work for your use case. It doesn't rely on extension and uses file content to determine the encoding. It doesn't need BOM also.