Hi Leo, I know this is an old thread. However...
DOpus makes my life immeasurably easier. THANK YOU. However, I've become so used to file wrangling the files our 43TB SAN with the ease provided by your efforts that when things don't go as planned, I get frustrated.
I routinely encounter external files with the UTF-8 character U+0097 in file names (UTF-8 Control Character "End of Guarded Area") and U+0096 ("Start of Guarded Area"). It took me forever to just figure out why my scripted renames were failing, then even longer to identify the offending character [see note 1 below]. I finally discovered the pain of UTF zero-width characters, but now I'm stuck at how to fix these filenames efficiently using DOpus renaming. I encounter dozens of these files daily.
I wish simply fixing the filenaming problem at the source was an option. It isn't.
To answer your question, the invisible characters that DOpus is (I think) ignoring or not displaying cause a problem because DOpus doesn't seem to be able to handle renames using a regex in either scripts or the rename dialog that would reference the invisible UTF-8 character and essentially just delete the invisible character. My rename scripts use the regex syntax \x{0097} as provided here:
' Remove zero-length spaces
regex.Pattern = "\x{0097}"
strNameOnly = regex.Replace(strNameOnly, "")
(FWIW, I also tried \u{0097})
The regex behavior I anticipated is that the zero-length invisible UTF-8 control character will be replaced with Null (that is, deleted). Nope. That particular regex in the script does nothing although the rest of the script works as expected. I have also tried a GUI rename in DOpus using:
RenameType: Regular Expressions Find and Replace
Oldname: \u{0097}
Newname:
I get an "Error in Search Pattern. Trailing Backslash" (I tried it without the escape also. The it does nothing when run).
I have banged my head on this for weeks and have digested more than I ever wanted to know about UTF non-printing characters, including several very complex explanations on StackOverflow, SuperUser, and the Notepad++ forums, among many others--all of which in the end only served to confuse me (e.g., https://tinyurl.com/ypmjb8f2, and Visualization for zero-width characters | Notepad++ Community). Many of the posts mention in great detail that this is a known and persistent headache with UTF-8 but the solutions I have tried have failed. I'm not a programmer and so the PERL/Bash/etc scripts I've seen elsewhere are pretty far above my paygrade. I am pinning my hopes on DOpus--once again--to the rescue.
At this point I have only been able to weed out the offending files by running the rename script on a batch of files I am cleaning up and visually hunting for "failed" renames, then copying the filenames using DOpus (Copy -> Other -> Short Names Only), look for the offending UTF-8 control characters, and rename them manually. A big burden for an otherwise easy task, but at least I'm halfway there.
Can you help? Can anyone that's solved this? Surely I am not alone. There must be a solution I'm overlooking.
Scott
NOTE 1 (for those that are struggling with this issue too)
Unicode control characters can appear in a filename but are not normally displayed by the Windows and MacOS operating systems. DOpus also ignores these characters in both display and filename handling.
To locate the offending character I used the terrific text wrangling program Notepad++. I used DOpus to copy the actual filenames, then pasted that list into a blank Notepad++ text document. I then selected View->Show Symbol->Show All Symbols to display the (normally) invisible UTF-8 control characters.
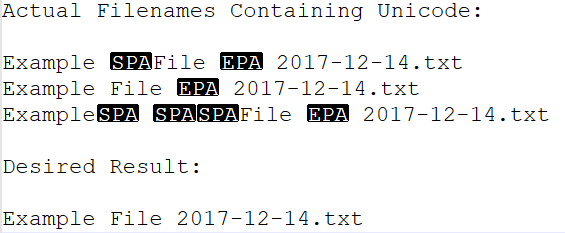
Thus, the filenames normally displayed in DOpus appear as:

Are actually:

The "SPA" and the "EPA" characters are where my issue lies.