I have been using this tokenizer-based script which parses filenames and automatically creates Everything Search strings. Most of my music, videos, documents follow similar naming schemes, and this script helps me to find say, any album from same artist, movies from same year, files with the same tags etc. Now that v13 and ES became tightly integrated it got even more powerful. Because of my work, I am very well versed with regexps but know they might be a bit scary for other people.
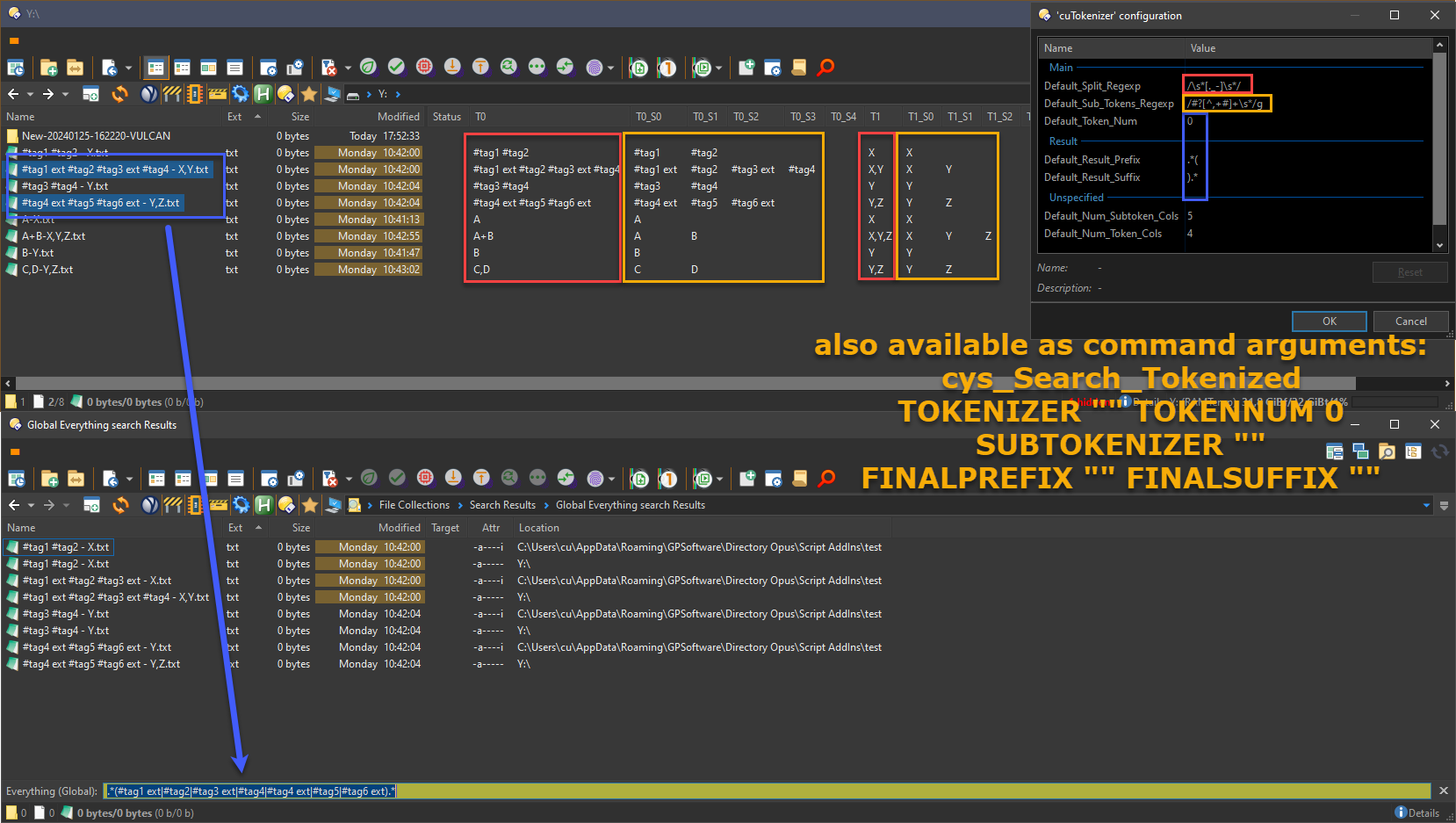
Basically, one tokenizer (red) splits the file name into tokens (outer parts) and a 2nd subtokenizer (yellow) picks certain portions of each token into smaller, inner parts, which are shown as Tx & Tx_Sy columns in the screenshot respectively. (Technically only outer one is a tokenizer, the inner one is match groups instead, that's why 2nd one always must have /g). The subtokens then are put together into an "OR" like regexp together and passed on to ES (blue). And if multiple files are selected then all subtokens across all files are collected. If all arguments are set to "" or 0, then it performs whole filename_stem as tokens. This has become a major part of my workflow: I select files related to one customer project (same prefix on all files for the same project), find e-books on a certain topic, etc pp In the screenshot, I select 2 files, press Alt-S and it auto-starts an ES global regexp search. The reason why there are also "final prefix" and "final suffix" arguments is when I was using external ES before v13, I would add e.g. ".exe$" at the end to filter further by exe files or add "^M:" in front to filter further by drive, etc. Of course they are available as command arguments. I see enormous potential for other people as well as it is; instead of dictating a certain naming scheme for a specific purpose, anybody can define their own, and use different regexps for different purposes. For example, tags in metadata are nice, but not all file formats support them and they require peeking into a deeper layer of access and reading files, whereas tags in filenames are blazing fast, since they're already read into memory, and the rest is ES magic running at speed of light.
My personal version uses the "tokennum" (default 0, but can be overridden via settings or command arguments) for picking the outer token#. But I decided to extend it and create visualization columns, since I already have this information and thought it might help others to create rename scripts (using the script columns) or to get more familiar with regexps or some other purpose, but it's getting into gold-plating territory (basically going way overboard).
Is there anybody interested in the columns version for whatever reason, or can come up with genius application ideas? Maybe people with less regexp experience? Or should I remove the columns and release the leaner script?