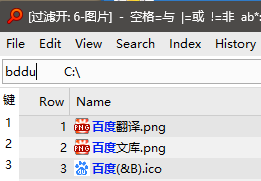
For a long time, in DOpus, there has been a problem with matching heteronyms in Chinese characters using the first letter of pinyin. DOpus can match only one pronunciation, and cannot match the correct letter based on different phrases.
Pinyin is supported since 2020.1 Directory Opus 12.19.1 (Beta)
Although this issue has already been mentioned, I still want to raise it again...
https://resource.dopus.com/t/pinyin-support-should-be-enhanced/50208
For example:
"长" is a polyphonic character (heteronym), which is pronounced differently depending on the context :
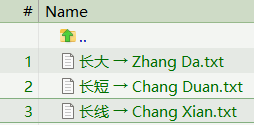
长 → Zhang / Chang (two pronunciations)
长大 → Zhang Da : means "grow up"
长短 → Chang Duan : means "long and short"
长线 → Chang Xian : means "long line"
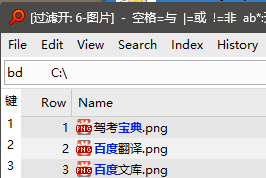
Now the problem with filtering by pinyin :
filter "cd" , we will get file :
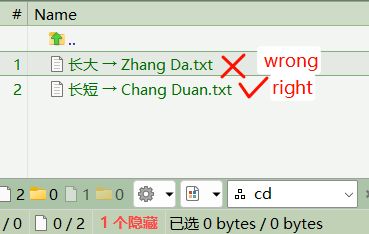
but what we expect is only "长短 → Chang Duan.txt".
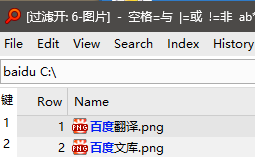
filter "zd" , we will get nothing:
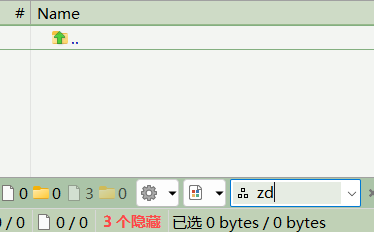
but what we expect is only "长大 → Zhang Da.txt"
The correct match is:
zd → 长大
cd → 长短
cx → 长线
z / c → 长 ( z or c can both match single "长", non-word) ↓
"他的手指很长" : 长 is non-word here, it pronounce Chang.
"他长我三岁" : 长 is non-word here, it pronounce Zhang.
Resolution: How to match them correctly?
Here is an open-source repo for better matching heteronyms in Chinese characters:
A multilingual, flexible and fast string, glob and regex matcher. Support 拼音匹配 (Chinese pinyin match) and ローマ字検索 (Japanese romaji match).
This open-source library adopts the most permissive MIT License.
It is easy to use ahk script to do the correct matching,
IbPinyin_Match(pattern, haystack, notations := IbPinyin_AsciiFirstLetter | IbPinyin_Ascii, &start := 0, &end := 0)
{
return IbPinyin_FindMatch(pattern, haystack, &start, &end, notations)
}
Could you please introduce this powerful matching algorithm into DOpus? ![]()